WebReference.com - Chapter 17 of JavaScript: The Definitive Guide (4th Ed), from O'Reilly & Associates (2/15)
[previous] [next] |
JavaScript: The Definitive Guide (4th Ed)
An Overview of the DOM
The DOM API is not particularly complicated, but before we can begin our discussion of programming with the DOM, there are a number of things you should understand about the DOM architecture.
Representing Documents as Trees
HTML documents have a hierarchical structure that is represented in the DOM as a tree
structure. The nodes of the tree represent the various types of content in a document. The tree
representation of an HTML document primarily contains nodes representing elements or tags such as
<body> and <p> and nodes representing strings of text. An HTML document may also contain nodes representing HTML comments.[1] Consider the following simple HTML document:
<html>
<head>
<title>Sample Document</title>
</head>
<body>
<h1>An HTML Document</h2>
<p>This is a <i>simple</i> document.
</body>
</html>The DOM representation of this document is the tree pictured in Figure 17-1.
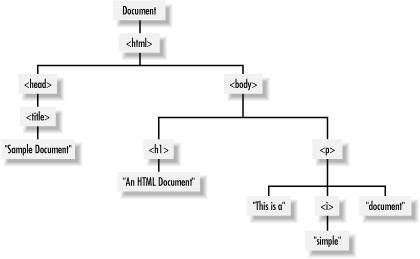
Figure 17-1. The tree representation of an HTML document
If you are not already familiar with tree structures in computer programming, it is helpful to know that they borrow terminology from family trees. The node directly above a node is the parent of that node. The nodes one level directly below another node are the children of that node. Nodes at the same level, and with the same parent, are siblings. The set of nodes any number of levels below another node are the descendants of that node. And the parent, grandparent, and all other nodes above a node are the ancestors of that node.
Nodes
The DOM tree structure illustrated in Figure 17-1 is represented as a tree of various types of Node objects. The Node interface[2] defines properties and methods for traversing and manipulating the tree. The childNodes property of a Node object returns a list of children of the node, and the firstChild, lastChild, nextSibling, previousSibling, and parentNode properties provide a way to traverse the tree of nodes. Methods such as appendChild( ), removeChild( ), replaceChild( ), and insertBefore( ) enable you to add and remove nodes from the document tree. We'll see examples of the use of these properties and methods later in this chapter.
Types of nodes
Different types of nodes in the document tree are represented by specific subinterfaces of Node. Every Node object has a nodeType property that specifies what kind of node it is. If the nodeType property of a node equals the constant Node.ELEMENT_NODE, for example, you know the Node object is also an Element object and you can use all the methods and properties defined by the Element interface with it. Table 17-1 lists the node types commonly encountered in HTML documents and the nodeType value for each one.
|
Interface |
nodeType constant |
nodeType value |
|---|---|---|
|
Element |
Node.ELEMENT_NODE |
1 |
|
Text |
Node.TEXT_NODE |
3 |
|
Document |
Node.DOCUMENT_NODE |
9 |
|
Comment |
Node.COMMENT_NODE |
8 |
|
DocumentFragment |
Node.DOCUMENT_FRAGMENT_NODE |
11 |
|
Attr |
Node.ATTRIBUTE_NODE |
2 |
Table 17-1: Common node types
The Node at the root of the DOM tree is a Document object. The
documentElement property of this object refers to an Element object that represents the
root element of the document. For HTML documents, this is the <html> tag that is
either explicit or implicit in the document. (The Document node may have other children, such as Comment
nodes, in addition to the root element.) The bulk of a DOM tree consists of Element objects, which
represent tags such as <html> and <i>, and Text objects, which
represent strings of text. If the document parser preserves comments, those comments are represented
in the DOM tree by Comment objects. Figure 17-2 shows a partial class hierarchy for these and other core
DOM interfaces.
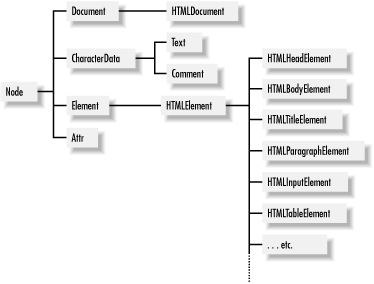
Figure 17-2. A partial class hierarchy of the core DOM API
Attributes
The attributes of an element (such as the src and width attributes of an <img> tag) may be queried, set, and deleted using the getAttribute( ), setAttribute( ), and removeAttribute( ) methods of the Element interface.
Another, more awkward way to work with attributes is with the getAttributeNode( ) method, which returns an Attr object representing an attribute and its value. (One reason to use this more awkward technique is that the Attr interface defines a specified property that allows you to determine whether the attribute is literally specified in the document, or whether its value is a default value.) The Attr interface appears in Figure 17-2, and it is a type of node. Note, however, that Attr objects do not appear in the childNodes[] array of an element and are not directly part of the document tree in the way that Element and Text nodes are. The DOM specification allows Attr nodes to be accessed through the attributes[] array of the Node interface, but Microsoft's Internet Explorer defines a different and incompatible attributes[] array that makes it impossible to use this feature portably.
1. The DOM can also be used to represent XML documents, which have a more complex syntax than HTML documents, and the tree representation of such a document may contain nodes that represent XML entity references, processing instructions, CDATA sections, and so on. Most client-side JavaScript programmers do not need to use the DOM with XML documents, and although the XML-specific features of the DOM are covered in the DOM reference section, they are not emphasized in this chapter.
2. The DOM standard defines interfaces, not classes. If you are not familiar with the term interface in object-oriented programming, you can think of it as an abstract kind of class. We'll describe the difference in more detail later in this DOM overview.
[previous] [next] |
Created: November 28, 2001
Revised: November 28, 2001
URL: https://webreference.com/programming/javascript/definitive/chap17/2.html
 Find a programming school near you
Find a programming school near you