Processing Instructions
Processing Instructions
Although it isn't all that common, sometimes you need to embed application-specific instructions into your information, to affect how it will be processed. XML provides a mechanism to allow this, called processing instructions or, more commonly, PIs. These allow you to enter instructions into your XML which are not part of the actual document, but which are passed up to the application.
<?xml version='1.0' encoding='UTF-16' standalone='yes'?>
<name nickname='Shiny John'>
 <first>John</first>
 <!--John lost his middle name in a fire-->
 <middle/>
 <?nameprocessor SELECT * FROM blah?>
 <last>Doe</last>
</name>
There aren't really a lot of rules on PIs. They're basically just a "<?", the name of the application that is supposed to receive the PI (the PITarget), and the rest up until the ending "?>" is whatever you want the instruction to be. The PITarget is bound by the same naming rules as elements and attributes. So, in this example, the PITarget is nameprocessor, and the actual text of the PI is SELECT * FROM blah.
PIs are pretty rare, and are often frowned upon in the XML community, especially when used frivolously. But if you have a valid reason to use them, go for it. For example, PIs can be an excellent place for putting the kind of information (such as scripting code) that gets put in comments in HTML. While you can't assume that comments will be passed on to the application, PIs always are.
Is the XML Declaration a Processing Instruction?
At first glance, you might think that the XML declaration is a PI that starts with xml. It uses the same "<? ?>" notation, and provides instructions to the parser (but not the application). So is it a PI?
Actually, no: the XML declaration isn't a PI. But in most cases it really doesn't make any difference whether it is or not, so feel free to look at it as one if you wish. The only places where you'll get into trouble are the following:
q Trying to get the text of the XML declaration from an XML parser. Some parsers erroneously treat the XML declaration as a PI, and will pass it on as if it were, but many will not. The truth is, in most cases your application will never need the information in the XML declaration; that information is only for the parser. One notable exception might be an application that wants to display an XML document to a user, in the way that we're using IE5 to display the documents in this book.
q Including an XML declaration somewhere other than at the beginning of an XML document. Although you can put a PI anywhere you want, an XML declaration must come at the beginning of a file.
Try It Out – Dare to be Processed
Just to see what it looks like, let's add a processing instruction to our Weird Al XML:
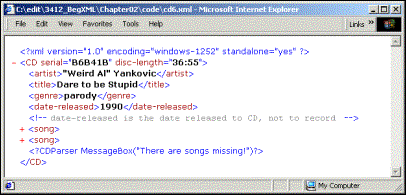
1. Make the following changes to cd5.xml and save the file as cd6.xml:
<?xml version='1.0' encoding='windows-1252' standalone='yes'?>
<CD serial='B6B41B'
   disc-length='36:55'>
 <artist>"Weird Al" Yankovic</artist>
 <title>Dare to be Stupid</title>
 <genre>parody</genre>
 <date-released>1990</date-released>
 <!--date-released is the date released to CD, not to record-->
 <song>
   <title>Like A Surgeon</title>
   <length>
     <minutes>3</minutes>
     <seconds>33</seconds>
   </length>
   <parody>
     <title>Like A Virgin</title>
     <artist>Madonna</artist>
   </parody>
 </song>
 <song>
   <title>Dare to be Stupid</title>
   <length>
     <minutes>3</minutes>
     <seconds>25</seconds>
   </length>
   <parody/>
 </song>
 <?CDParser MessageBox("There are songs missing!")?>
</CD>
In IE5, it looks like this:
|
|
How It Works
For our example, we are targeting a fictional application called CDParser, and giving it the instruction MessageBox("There are songs missing!"). The instruction we gave it has no meaning in the context of XML itself, but only to our CDParser application, so it's up to CDParser to do something meaningful with it.
Illegal PCDATA Characters
There are some reserved characters that you can't include in your PCDATA because they are used in XML syntax.
For example, the "<" and "&" characters:
<!--This is not well-formed XML!-->
<comparison>6 is < 7 & 7 > 6</comparison>
Viewing the above XML in IE5 would give the following error:
|
|
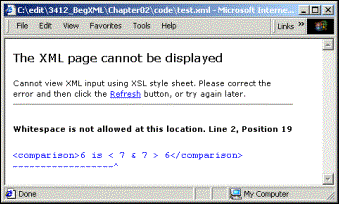
This means that the XML parser comes across the "<" character, and expects a tag name, instead of a space. (Even if it had got past this, the same error would have occurred at the "&" character.)
There are two ways you can get around this: escaping characters, or enclosing text in a CDATA section.
Escaping Characters
To escape these two characters, you simply replace any "<" characters with < and any "&" characters with &. The above XML could be made well-formed by doing the following:
<comparison>6 is < 7 & 7 > 6</comparison>
Which displays properly in the browser:
|
|
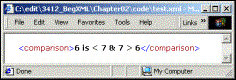
Notice that IE5 automatically un-escapes the characters for you when it displays the document, in other words it replaces the < and & strings with < and & characters.
< and & are known as entity references. The following entities are defined in XML:
q & – the & character
q < – the < character
q > – the > character
q ' – the ' character
q " – the " character
Other characters can also be escaped by using character references. These are strings such as &#nnn;, where "nnn" would be replaced by the Unicode number of the character you want to insert. (Or &#xnnn; with an "x" preceding the number, where "nnn" is a hexadecimal representation of the Unicode character you want to insert. All of the characters in the Unicode specification are specified using hexadecimal, so allowing the hexadecimal numbers in XML means that XML authors don't have to convert back and forth between hexadecimal and decimal.)
Escaping characters in this way can be quite handy if you are authoring documents in XML that use characters your XML editor doesn't understand, or can't output, because the characters escaped are always Unicode characters, regardless of the encoding being used for the document. As an example, you could include the copyright symbol (ã) in an XML document by inserting © or ©.
CDATA Sections
If you have a lot of "<" and "&" characters that need escaping, you may find that your document quickly becomes very ugly and unreadable. Luckily, there are also CDATA sections.
CDATA is another inherited term from SGML. It stands for Character DATA.
Using CDATA sections, we can tell the XML parser not to parse the text, but to let it all go by until it gets to the end of the section. CDATA sections look like this:
<comparison><![CDATA[6 is < 7 & 7 > 6]]></comparison>
Everything starting after the <![CDATA[ and ending at the ]]> is ignored by the parser, and passed through to the application as is. In this trivial case, CDATA sections may look more confusing than the escaping did, but in other cases it can turn out to be more readable. For example, consider the following example, which uses a CDATA section to keep an XML parser from parsing a section of JavaScript:
<script language='JavaScript'><![CDATA[
function myFunc()
{
   if(0 < 1 && 1 < 2)
       alert("Hello");
}
]]></script>
If you aren't familiar with JavaScript and want to know what the above script does, take a look at the tutorial in Appendix D.
This displays in the IE5 browser as:
|
|
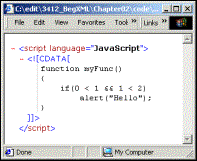
Notice the vertical line at the left hand side of the CDATA section. This is indicating that although the CDATA section is indented for readability, the actual data itself starts at that vertical line. This is so we can visually see what white space is included in the CDATA section.
If you're familiar with JavaScript, you'll probably find the if statement much easier to read than:
if(0 < 1 && 1 < 2)
Try It Out – Talking about HTML in XML
Suppose that we want to create XML documentation, to describe some of the various HTML tags in existence.
2. We might develop a simple document type such as the following:
<HTML-Doc>
 <tag>
   <tag-name></tag-name>
   <description></description>
   <example></example>
 </tag>
</HTML-Doc>
In this case, we know for sure that our <example> element is going to need to include HTML syntax, meaning that there are going to be a lot of "<" characters included. This makes <example> the perfect place to use a CDATA section, meaning that we don't have to search through all of our HTML code looking for illegal characters. To demonstrate, lets document a couple of HTML tags.
Create a new file and type this code:
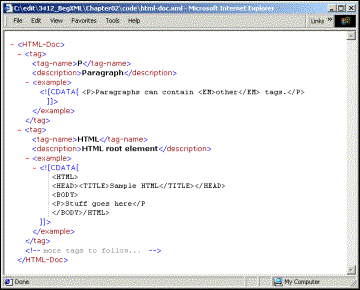
<HTML-Doc>
 <tag>
   <tag-name>P</tag-name>
   <description>Paragraph</description>
   <example><![CDATA[
<P>Paragraphs can contain <EM>other</EM> tags.</P>
]]></example>
 </tag>
 <tag>
   <tag-name>HTML</tag-name>
   <description>HTML root element</description>
   <example><![CDATA[
<HTML>
<HEAD><TITLE>Sample HTML</TITLE></HEAD>
<BODY>
<P>Stuff goes here</P
</BODY>/HTML>
]]></example>
 </tag>
 <!--more tags to follow...-->
</HTML-Doc>
Save this document as html-doc.xml and view it in IE5:
|
|
How It Works
Because of our CDATA sections, we can put whatever we want into the <example> elements, and don't have to worry about the text being mixed up with the actual XML markup of the document. This means that even though there is a typo in the second <example> element (the </P is missing the >), our XML is not affected.
![]()
Produced by Michael Claßen
All Rights Reserved. Legal Notices.
URL: https://www.webreference.com/xml/resources/books/beginningxml/34120201.htm
Created: Jan. 05, 2001
Revised: Jan. 05, 2001
 Find a programming school near you
Find a programming school near you