Scripting in the Browser - Part 2 | Page 2
[previous] [next]
Scripting in the Browser - Part 2
Using JavaScript with the DOM
Let's use JavaScript to work with the xDOM library in a test web page. You can find this page, test.htm, with your resources. It contains code that shows you how to perform many simple XML tasks using the xDOM library.
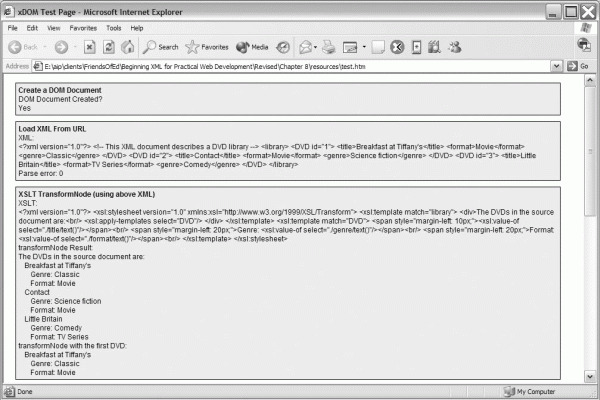
Figure 8-3 shows test.htm displayed in Firefox 1.5.
The test page contains a series of <div> elements that illustrate the following:
|
Note: The test page uses the xDOM library to write cross-browser code. Apart from creating the DOM Document, all of this code in test.htm works correctly in IE. However, in Mozilla, the xDOM library manages several of the function calls. You can find out how to carry out the tasks natively in Mozilla by looking at the "Initializing in Mozilla" section earlier in this chapter.
Let's work through each section of the test.htm page so you can see how the code works. The resource file contains several comments that aren't included in the code that follows.
Creating DOM Document Objects and Loading XML
To start, you need to create a DOM Document object so that you can work with the external XML text. When test.htm loads, it calls the runTest() function. The runTest() function starts by calling the doCreateDOMDocument() function.
Creating a DOMDocument Object
The doCreateDOMDocument() function creates the DOM Document:
The line
creates the DOM Document using the method from the xDOM library.
When the function runs, the value of oDOMDocument is set to reference a new DOM Document object. The code tests that the object exists by calling the createElement() method. Using the getElementById() method with the innerHTML property displays either the value Yes or No in the web page. Figure 8-4 shows the resulting output from this function.

Loading XML from a URL
Once the DOM Document object exists, you can use it to load DVD.xml by calling the doLoadXMLFromURL() function:
The function creates a DOM Document, sets the onreadystatechange handler, and loads the XML document. Figure 8-5 shows how the JavaScript processing occurs.
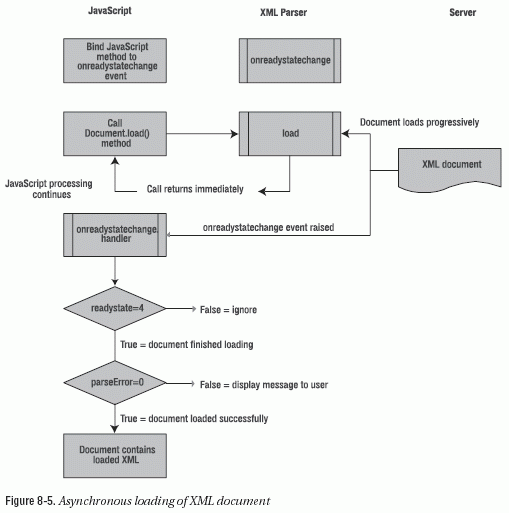
The doLoadXMLFromURL() function sets the onreadystatechange handler to the onLoad_LoadXMLFromURL() function. It then calls the load() method to load the file DVD.xml asynchronously. The load() function call returns immediately while the XML document loads in the background. This allows other JavaScript processing to continue while the XML document loads.
The onreadystatechange event handler function determines when the XML file has finished loading so it can be processed:
The onreadystatechange event is raised each time the readyState property changes. The document is completely loaded when readyState is equal to 4. When the document loads, the code shows the XML content in the divXMLFromURLRawXML element. It also displays the value of parseError.
Note: When the browser loads an invalid XML file, the loading process completes successfully and readyState equals 4. Because of this, the code needs to include an additional check of the parseError property of the DOM Document to see the outcome of the load. The test.htm document includes an example of loading a document that is not well formed.
Figure 8-6 shows the appearance of the test page when the XML file loads successfully.

Figure 8-7 shows what happens in Firefox when you load a document that isn't well formed.

IE acts a little differently from Mozilla, as it won't display any XML content from a document that is not well formed. In IE, you wouldn't see any XML output at all.
XSLT Manipulation
In Chapters 6 and 7, I worked through XSLT transformation techniques that allowed you to generate XHTML content from XML. MSXML includes the methods transformNode() and transformNodeToObject(). As these methods aren't available in Mozilla, they've been added to the xDOM library. The transformNode() method returns the transformed content as a string, whereas transformNodeToObject() populates the DOM Document object passed as a parameter.
The MSXML transformNodeToObject() method can send the results to an IStream, which can stream information into Microsoft components. However, because this is Microsoftspecific, xDOM doesn't support the feature.
Applying Stylesheets to Documents
The test page contains an example that uses transformNode() and transformNodeToObject():
The code must make sure that the variable passed into transformNodeToObject() is initialized. If you use the transformNodeToObject() method, you also need to make sure that the XSLT stylesheet generates valid XML. Note that the example XSLT file, test.xslt, uses a <div> tag to wrap the transformation output, thereby creating a single root element in the transformation.
Figure 8-8 shows the XSLT document and the transformation resulting from test.xslt. It also shows a single node transformation.

MSXML Template and Processor Objects
MSXML includes two objects that you can use together to compile an XSLT stylesheet for several transformations. This functionality increases efficiency and is most suited to a server-side environment, where the same stylesheet runs with each page request. I won't cover these objects here, but you can find out more about the IXSLProcessor and IXSLTemplate interfaces in the MSXML documentation.
DOM Manipulation and XSLT Combined
Because the transformNode() methods are declared on the Node interface, you can combine the power of DOM iteration with XSLT by selecting a single node for transformation:
In this case, I've matched the first DVD element using getElementsByTagName("DVD")[0]. The template matches this element:
Only this node is transformed.
Extracting Raw XML
One task for developers is retrieving XML content from the DOM as a string. The W3C DOM specification is silent on how to achieve this task. MSXML provides the read-only xml property on the Node interface. This returns the raw XML from a specific node as text.
xDOM provides a Mozilla version of this property. There is no specific example in the test.htm document, but the property is used in many of the other examples.
Note: The xml property is provided within the Node interface. Because the Document interface inherits the Node interface, you can access this property on the
DOM Document object:
The following code sets the variable strXML to equal the serialized contents of the oXMLFromString DOM Document:
[previous] [next]
URL:
 Find a programming school near you
Find a programming school near you