PPK on JavaScript: The DOM - Part 2/Page 3 | 2
[previous] [next]
PPK on JavaScript: The DOM - Part 3
I: nodeLists
Some W3C DOM methods and properties return nodeLists: lists of all nodes that meet a certain criterion. Of these, getElementsByTagName() is by far the most important. It returns a nodeList that contains all elements that have a certain tag name. Let's take a close look at nodeLists and their dangers.
Superficially, nodeLists look like arrays. They accept an index number between square brackets, and return the node with that index number. For instance:
x is the second paragraph (with index 1) in the document.
item() Not Necessary: All nodeLists also have an item() method. It requires an index number, and returns the node with that index number. These two calls do exactly the same thing:
var fourthP = x[3];
var fourthP = x.item(3);
item() is meant for other languages in which nodeLists don't behave as arrays. In JavaScript you never need it.
All nodeLists also have a length property that gives the length of the nodeList:
x is the number of paragraphs in the document.
These two features combined mean that we often use nodeLists as arrays:
In 5L I said that nodeLists can be seen as read-only arrays. The time has come to amend that definition somewhat. It's true that you cannot directly add or remove elements to or from a nodeList. For example, if I run the following script, nothing happens, not even an error message:
But nodeLists are not static. In fact, they're dangerously dynamic, because they immediately reflect all changes in the document. For instance, take this code:
This creates a nodeList that holds all paragraphs in the document and alerts its length. Then another paragraph is added to the document, and again the script alerts the length of the nodeList. The nodeList has now increased by one because there's one more paragraph in the document. The nodeList is updated automatically, and doesn't require a new getElementsByTagName() call to see the changes.
The danger
To explain why this is dangerous, let's take another look at Usable Forms. When the script starts up, it has to go through all <tr> (or <div>) tags in the document and move those elements with a rel attribute to the waiting room. Superficially, this seems simple:
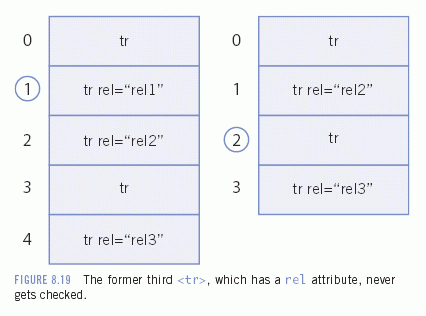
Note that the waiting room is not a part of the document. Say that the second <tr> in the document is the first one with a rel attribute. When the script reaches the second <tr> (with index 1), it sends it to the waiting room, i.e., outside the document. Then it moves on to index 2 and checks again.
The problem is that the nodeList immediately updates and therefore the index numbering of the <tr>s has changed! We removed the second <tr> (x[1]), but this means that the former third <tr> (x[2]) has now become the second one (x[1]). Since the script moves on to index 2, it never checks this <tr>, and continues with the former fourth <tr> (which was x[3], and is now x[2]).
That's why nodeLists are so dangerously dynamic. While looping through all elements of a nodeList, you should never add or remove these elements to or from the document, or even move them, because doing so messes up your for() loops and results in very odd bugs.
Helper arrays
Helper arrays are a good and easy solution to the nodeList problem we just discussed. I always use them if I have to go through a nodeList and remove certain of its elements. The principle is simple: if a certain element should be removed, I add it to the helper array. When the for() loop through the nodeList has ended, I start up a new loop to go through this array and remove the <tr>s from the document.
When working with the helper array, I always use push() and shift(), the two array methods that I promised an example of in Section 5L. In addition, it's useful to note that the helper array does not have to survive the second loop: by the end, it has done its duty.
The script goes through all <tr>s and, if one has a rel attribute, pushes it into the helper array hiddenFields. When it has looped through the entire nodeList, hiddenFields contains pointers to all <tr>s that should be removed.
Then the script starts up a while() loop that sees if the array still has a length, i.e., if it still contains elements. Each loop works on hiddenFields[0], i.e., the first array element that's still available.
After some administration, the script replaces the <tr> with a marker (see Section 8L) and then appends it to the waitingRoom. This causes it to be removed from the document, but it doesn't disappear from hiddenFields. hiddenFields, after all, is a real array, not a nodeList, and is therefore not updated automatically.
That's why the script uses shift() in the last line: this method returns the first element in an array and simultaneously removes it from the array. Therefore the <tr> is removed from the array, and this causes the next element to become hiddenFields[0], and the loop is repeated until hiddenFields doesn't contain any more elements (i.e., its length is 0).
[previous] [next]
URL:
 Find a programming school near you
Find a programming school near you