PPK on JavaScript: The DOM - Part 2 | 2
[next]
PPK on JavaScript: The DOM - Part 3
H: Text nodes
In general, text nodes are easy to work with. The W3C DOM defines a few methods for getting and changing texts, but the Core string methods and properties we discussed in 5F are more useful and versatile.
nodeValue
Many element nodes hold a text node:
Often you want to read or change the text in the text node. You generally do this through the nodeValue of the text node, which is usually the firstChild of an element node:
You access the correct element node, move to its first child (the text node), and then access its nodeValue. The alert shows the text 'I am a JavaScript hacker.' The third line assigns a new value to the text node, and of course this change is immediately visible in the browser.
The x.firstChild works only if the text node is actually the first child of the element. If that's not the case, accessing the text node is somewhat harder:
Now x.firstChild is the <br /> element node, which doesn't have a nodeValue. You have to access the text node as x.lastChild or x.childNodes[1].
Fortunately, this is a rare case; most common text containers like <p>, <li>, or <a> contain exactly one node: a text node.
Empty text nodes
Normal text nodes are easy to work with. Unfortunately, there are also empty text nodes. They are by far the most useless and annoying feature of the W3C DOM, but you'll encounter them in every HTML document you work with.
Consider this HTML snippet:
How many child nodes does the
have? Two, right? The<h1> and the <p>?
Wrong.
The <body> has five child nodes. Two of them are element nodes, the other three are empty text nodes. There is text between the tags: a hard return between the
<h1>, between the </h1> and the <p>, and between the </p> and the </body>. Since spaces, hard returns, and tabs are text content, the W3C DOM creates text nodes to hold them.
No Empty Text Nodes in Explorer: Explorer Windows does not support empty text nodes. This is an excellent idea, but unfortunately all other browsers disagree, and thus incompatibilities are born.
Empty Text Nodes Are not Empty: Empty text nodes are not really empty; they contain whitespace characters. Nonetheless, they are useless in an HTML document, since HTML interprets a sequence of whitespace characters as either a space or a hard return— whichever suits the document best. As far as their practical usefulness goes, these text nodes might as well be empty.
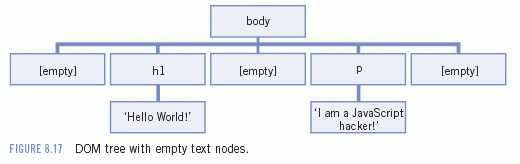
I purposely omitted empty text nodes from the DOM overview in 8A because they would have made my explanations too complicated and dense. In fact, they make working with the DOM complicated and dense, too.
For instance, take this script:
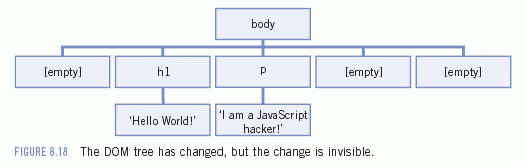
This seems simple, right? Take the paragraph and insert it before its previous sibling: the <h1>. It works fine in Explorer.
Unfortunately, in all the other browsers, the
's previous sibling is not the <h1> but the empty text node between the </h1> and the <p>. The DOM tree changes, but not the way you'd like it to change.
One way to remove these incompatibilities is to turn all empty text nodes off. This could be done by removing all whitespace from your HTML:
Hello world!
I am a JavaScript hacker!
Now the <body> really has only two child nodes. Nonetheless, working in HTML files without any whitespace becomes annoying in a hurry.
[next]
URL:
 Find a programming school near you
Find a programming school near you