Performance Optimizations for High Speed JavaScript [con't]
Technique 4: Use buffering to process data in optimal sizes
For years, server engineers and supercomputer designers have known that buffering is a key component of increasing the speed of data processing, transfer and storage, and communication protocols. Any JavaScript program that does data processing--be it HTML-ization of text, base64 encoding, MD5 digests, email encryption--can benefit from buffering.
Given your typical computer hardware, your operating system, and your browser, any JavaScript program that does data processing has an optimal size of input where the data processing proceeds at the highest rate. Your job in optimizing your program is to find this optimal size and to buffer your data to match that size. This "buffering" can be as simple as splitting your data into substrings and processing each piece separately.
Buffering is the vaguest type of optimization that we discuss in this article, because it requires experimentation with your computer programs in order to find out which buffer sizes will process your data in the fastest possible way. In a sense, buffering is the most valuable technique of them all. Hopefully, you'll understand the point of using buffers and how to start implementing them by the time you finish reading this page. To help you see how buffers improve performance, I offer a historical example of buffering and then a fun contest result that relied on buffers to win.
A historical use of buffering
There are still some family reunion pages or lists of email addresses that are encrypted with Web Cipher 2, but most Web pages that used it were created before anyone ever heard of Google. Many of them aren't anywhere to be seen, part of the silent history of the Internet. The purpose of Web Cipher 2 was to provide SSL-level encryption and data security for free without the need for SSL certificates or the associated costs.
The biggest challenge I faced in writing the code for Web Cipher was to make it fast enough on the computers of the day, like 333 MHz iMacs. (Combined with Mac OS 8.6, these computers were one of the longest lasting systems I've ever used. The processors were extremely fast, probably six to ten times faster than some 333 MHz processors that you may have had experience with, and the computers could almost match the performance of 2004 computers when 512 MB of RAM was added. Many high schools were still using these iMacs years later.)
I determined that encrypting the data in blocks of 64 bytes enabled me to maximize the encryption speed and reach 15 KB per second on an iMac. That was great, considering that many available encryption methods for JavaScript could only reach a few hundred bytes per second, and often were less secure as well.
Quoting from the description of Web Cipher, "Web Cipher is a client-side, cryptographically secure document encryption technology. It allows even an inexperienced Web author to establish virtually uncrackable safety measures on confidential data. Web Cipher is also fast, substantially overcoming the problem of speed in browser-based cryptology. It averages almost 15K per second in real-world tests on an iMac 333 MHz computer, much faster than similar utilities."
"Great," you say, "I realize I have to break my input into smaller pieces before processing it in order to increase speed, but how do I do it?"
That's a good question. You evaluate various buffer sizes and choose the one with the highest performance. Most algorithms suffer lower performance at both small and large buffer sizes, so a graph of the performance would resemble a parabola. You will see what I mean, after I show you the source code of the encryption functions.
A simple recursion is used in order to break down the input into
the desired block sizes. To create the test input for
encryption, I'm going to use the stringFill() function introduced
earlier.
Web Cipher 2 code that shows successful use of buffering
By using 64-byte block sizes for encryption, the
Web Cipher 2 algorithm enabled 1999 iMacs to securely
decrypt and encrypt Web pages on the client side
at 15 KB per second. Most client-side JavaScript encryption
algorithms were only able to execute at a few hundred bytes
per second at that time on available computer hardware
because they didn't use small size buffers or localized
variables.
(In fact, the first implementation of the MD5 algorithm
for JavaScript was written in 1996, all the way back to
the days of ".jvs" for JavaScript files instead of ".js."
It was called
calcMD5 by Henri Torgemane,
and on Mozilla Firefox 0.9 it was
more than ten times slower (338 ms)
than md5.js (29 ms).)
The table of the buffer sizes and resulting processing speeds are based on the same encryption code behind Web Cipher, but the performance measurements are obtained and tabulated from the results of modern-day computers, rather than the fruit-colored iMacs of yore. This shows that buffering is an optimization technique that still applies today.
Table of the buffer sizes and resulting processing speeds in milliseconds
On today's computers the fastest time is 256 bytes, with 15 milliseconds total encryption time. The original block size of 64 bytes is still fast, resulting in 31 milliseconds of encryption time. Smaller or larger block sizes increase the encryption time in a pattern similar to the graph of a parabola, but on large computers with lots of memory, it takes a big block size in order to slow down the encryption.
(Note that some browsers treat strings differently, and the change in speed due to buffering is smaller.)
Why do buffers help speed things up?
The reason that buffering works can be explained using the example of shopping. If you go to the store and buy only one item each trip, you waste time making a lot of trips. If you go to the store and buy too many items per trip you might not be able to fit everything in your car. Somewhere in between is the correct amount of groceries that you can buy and store per trip.
Another example is a waitress at a restaurant. If she carries one glass at a time it's inefficient. If she carries too many she might drop them or forget where to take them. If she carries just the right amount she will be the most efficient.
Today's fun buffering example
One of my favorite computer programs was a script that wrote one million numbers to a Web page. The object was to write the numbers 1 to 1,000,000 (or 0 to 999,999) to a Web page in normally sized text as fast as possible using JavaScript. The JavaScript output had to be nothing but "1" (space) "2" (space) "3" (...) (999999) (space) (1000000).
How could this be done quickly? In fact, how could one script author possibly obtain any advantage over anyone else?
The solution is to use buffering. Buffering applies not only to creating the data, but also to how large of a block of output is submitted to document.write(), how often the page is re-rendered after new content is emitted (possibly every time document.write() is used), and how much memory your graphics card can allocate to a huge amount of text to be stored in graphics memory and cached for display on your screen.
Also, in the document.write() function, you can separate your inputs by commas. This is done for a reason. Remember how slow it was to combine multiple strings? You should use commas between items in document.write() so strings can be written directly into the Web page (where they will be joined together by the HTML parser, which does the job faster than JavaScript).
A problem as simple as writing one million numbers is really a test of your graphics card, browser re-rendering algorithm and your JavaScript optimizations.
First try at one million numbers (well, one hundred thousand)
This program takes 3.417 seconds on Opera with a Core 2 Duo processor just to write 100,000 numbers. Firefox with a different processor took 5 seconds, and Internet Explorer couldn't run it without bringing up a false alarm about "This Web page may cause your computer to become unresponsive," which ruins any possible benchmarking. Getting to one million would nearly crash your computer. What a failure!
Is there any hope? Yes, because there was a script able to write one million numbers in about three seconds circa 2002, way back in the days of slow Pentium 3/4 processors and Internet Explorer 6.0.
In fact, on the slow library computer that I used, that script can still cook the goose of the code above--Internet Explorer can write the entire million numbers in 2.750 seconds without bringing up any warning about "unresponsive."
(By the way, that program is optimized for Internet Explorer. Firefox 2 cannot run it as fast, in contrast to most JavaScripts that you might find floating around on the Internet. Firefox 2 on the same computer is 3.375 seconds instead of 2.750.)
The winning one million number script
Note that the comma before the newline character avoids the extra computational cost of appending a short one-byte string onto a long string with hundreds or thousands of characters.
The technique that made this program win was dividing up the million numbers into a buffer of 1,000 numbers. The numbers weren't stored as text, but as a numerical array. An optimized function was made that would add 1,000 to each element of the array to change the numbers from 1, 2, ..., 1000 into 1001, 1002, ..., 2000, and then 2001, 2002, ..., 3000, etc.
In order to write the numbers to the Web page, the native built-in JavaScript
function join() was used, which doesn't suffer the performance
disadvantage incurred by JavaScripts which add strings together.
Also, do loops were used instead of while loops, because they are slightly
faster in most implementations of JavaScript.
Here are the results for various browsers--the only kind of "browser war" that I refer to in this article, because the one million number program provides a quality workout for any browser. The results are from an HP/Compaq SR5410F with Intel E2160 2 1.80 GHz and 1.00 GB RAM, running Windows Vista Home Premium SP1.
- IE 7.0 = 1950 milliseconds
- Safari 3.1.2 = 1092
- Opera = 3463
- Firefox 3.0.1 = Crashed, probably a problem related to a bad implementation of video card acceleration.
As far as I know, the only way to beat the winning program is the brute force approach
of writing a huge document.write() statement like this ... (abbreviated here for display purposes)
... but that wouldn't be elegant, would it?
By the way, it takes 11,000 milliseconds on Internet Explorer for this new version, so the code from 2002 still wins on IE. Internet Explorer isn't good at dealing with messy code or a lot of code, regardless of how efficient it might be. On Firefox, the new version goes down from 3.375 to 2.000 seconds.
Without using a buffer, writing one million numbers via document.write() takes 50 seconds with Firefox 2. By using a buffer which outputs a group of 1,000 numbers at
a time, only 2 seconds of total time is consumed with Firefox 2. Safari 3.1.2 on a Core 2 Duo
computer (1.8 GHz) can write one million numbers in less than three tenths of a second.
Internet Explorer isn't good at running complicated scripts or long statements such as
the one in this example, and so more sophisticated optimizations are necessary.
With these optimizations (which won a programming contest in 2002), Internet Explorer is able
to write one million numbers in 2.75 seconds on the same computer that was running
Firefox 2.
From the author
Thanks for reading about these JavaScript optimization techniques. My name is If you have any questions, feel free to send me an email.
Original: August 18, 2008
 Find a programming school near you
Find a programming school near you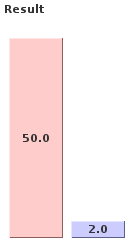{kind=link}