Performance Optimizations for High Speed JavaScript [con't]
Technique 3: Avoid adding short strings to long strings
Our previous result looked good--very good, in fact. The
improved function stringFill2()
is much faster due to the use of our first two optimizations. Would you believe it if I told you that it can be improved to be
many times faster than it is now?
Yes, we can accomplish that goal. Right now we need to explain how we avoid appending short strings to long strings.
The short-term behavior appears to be quite good, in comparison to our original function. Computer scientists like to analyze the "asymptotic behavior" of a function or computer program algorithm, which means to study its long-term behavior by testing it with larger inputs. Sometimes without doing further tests, one never becomes aware of ways that a computer program could be improved. To see what will happen, we're going to create a 200-byte string.
The problem that shows up with stringFill2()
Immutable means that you cannot change a string once it's created. By adding on one byte at a time, we're not using up one more byte of effort. We're actually recreating the entire string plus one more byte.
In effect, to add one more byte to a 100-byte string, it takes 101 bytes worth of work. Let's briefly analyze the computational cost for creating a string of N bytes. The cost of adding the first byte is 1 unit of computational effort. The cost of adding the second byte isn't one unit but 2 units (copying the first byte to a new string object as well as adding the second byte). The third byte requires a cost of 3 units, etc.
C(N) = 1 + 2 + 3 + ... + N = N(N+1)/2 = O(N2). The symbol
O(N2) is pronounced Big O of N squared, and it means that
the computational cost in the long run is proproportional to the square of the
string length. To create 100 characters takes 10,000 units of work,
and to create 200 characters takes 40,000 units of work.
This is why it took more than twice as long to create 200 characters than 100 characters. In fact, it should have taken four times as long. Our programming experience was correct in that the work is being done slightly more efficiently for longer strings, and hence it took only about three times as long. Once the overhead of the function call becomes negligible as to how long of a string we're creating, it will actually take four times as much time to create a string twice as long.
(Historical note: This analysis doesn't necessarily apply to strings in
source code, such as html = 'abcd\n' + 'efgh\n' + ... + 'xyz.\n', since the
JavaScript source code compiler can join the strings together before making them
into a JavaScript string object. Just a few years ago, the KJS implementation of JavaScript would freeze or
crash when loading long strings of source code joined by plus signs. Since
the computational time was O(N^2) it wasn't difficult to make Web pages
which overloaded the Konqueror Web browser or Safari, which used the KJS
JavaScript engine core. I first came across this issue when I was developing
a markup language and JavaScript markup language parser, and then I discovered what was causing the problem when I wrote my script for
JavaScript Includes.)
Clearly this rapid degradation of performance is a huge problem. How can we deal with it, given that we cannot change JavaScript's way of handling strings as immutable objects? The solution is to use an algorithm which recreates the string as few times as possible.
To clarify, our goal is to avoid adding short strings to long strings, since in order to add the short string, the entire long string also must be duplicated.
How the algorithm works to avoid adding short strings to long strings
Here's a good way to reduce the number of times new string objects are created. Concatenate longer lengths of string together so that more than one byte at a time is added to the output.
For instance, to make a string of length N = 9:
Doing this required creating a string of length 1, creating a string of length 2, creating a string of length 4, creating a string of length 8, and finally, creating a string of length 9. How much cost have we saved?
Old cost C(9) = 1 + 2 + 3 + 4 + 5 + 6 + 7 + 9 = 45.
New cost C(9) = 1 + 2 + 4 + 8 + 9 = 24.
Note that we had to add a string of length 1 to a string of length 0, then a string of length 1 to a string of length 1, then a string of length 2 to a string of length 2, then a string of length 4 to a string of length 4, then a string of length 8 to a string of length 1, in order to obtain a string of length 9. What we're doing can be summarized as avoiding adding short strings to long strings, or in other words, trying to concatenate strings together that are of equal or nearly equal length.
For the old computational cost we found a formula N(N+1)/2. Is there a formula for the new cost? Yes, but it's complicated. The important thing is that it is O(N), and so doubling the string length will approximately double the amount of work rather than quadrupling it.
The code that implements this new idea is nearly as complicated as the formula
for the computational cost. When you read it, remember that >>= 1 means to shift
right by 1 byte. So if n = 10011 is a binary number, then n >>= 1 results in the value
n = 1001.
The other part of the code you might not recognize is the bitwise and operator,
written &. The expression n & 1 evaluates true if the last binary digit of n is 1,
and false if the last binary digit of n is 0.
New highly-efficient stringFill3() function
It looks ugly to the untrained eye, but it's performance is nothing less than lovely.
Let's see just how well this function performs. After seeing the results, it's likely that you'll never forget the difference between an O(N2) algorithm and an O(N) algorithm.
stringFill1() takes 88.7 microseconds (millionths of a second) to create a 200-byte string,
stringFill2() takes 62.54, and stringFill3() takes only 4.608. What made this algorithm
so much better? All of the functions took advantage of using local function variables, but taking advantage of the second and third optimization techniques added
a twenty-fold improvement to performance of stringFill3().
Deeper analysis
What makes this particular function blow the competition out of the water?
As I've mentioned, the reason that both of these functions, stringFill1() and stringFill2(), run so slowly is that JavaScript strings are immutable. Memory cannot be reallocated to allow one more byte at a time to be appended to the string data stored by JavaScript. Every time one more byte is added to the end of the string, the entire string is regenerated from beginning to end.
Thus, in order to improve the script's performance, one must precompute longer length strings by concatenating two strings together ahead of time, and then recursively building up the desired string length.
For instance, to create a 16-letter byte string, first a two byte string would be precomputed. Then the two byte string would be reused to precompute a four-byte string. Then the four-byte string would be reused to precompute an eight byte string. Finally, two eight-byte strings would be reused to create the desired new string of 16 bytes. Altogether four new strings had to be created, one of length 2, one of length 4, one of length 8 and one of length 16. The total cost is 2 + 4 + 8 + 16 = 30.
In the long run this efficiency can be computed by
adding in reverse order and using a geometric series
starting with a first term a1 = N and having a common
ratio of r = 1/2. The sum of a geometric series is given
by a1 / (1-r) = 2N.
This is more efficient than adding one character to create
a new string of length 2, creating a new string of length 3,
4, 5, and so on, until 16. The previous algorithm used that
process of adding a single byte at a time, and the total cost of
it would be n (n + 1) / 2 = 16 (17) / 2 = 8 (17) = 136.
Obviously, 136 is a much greater number than 30, and so the previous algorithm takes much, much more time to build up a string.
To compare the two methods you can see how much faster
the recursive algorithm (also called "divide and conquer") is
on a string of length 123,457. On my FreeBSD computer this algorithm,
implemented in the stringFill3() function, creates the
string in 0.001058 seconds, while the original stringFill1() function
creates the string in 0.0808 seconds. The new function is
76 times faster.
The difference in performance grows as the length of the string becomes larger. In the limit as larger and larger strings are created, the original function behaves roughly like C1 (constant) times N2, and the new function behaves like C2 (constant) times N.
From our experiment we can determine the value of C1 to be C1 = 0.0808 / (123457)2 = .00000000000530126997, and the value of C2 to be C2 = 0.001058 / 123457 = .00000000856978543136. In 10 seconds, the new function could create a string containing 1,166,890,359 characters. In order to create this same string, the old function would need 7,218,384 seconds of time.
This is almost three months compared to ten seconds!
Impressed? Continue to the next page to learn about "buffering."
 Find a programming school near you
Find a programming school near you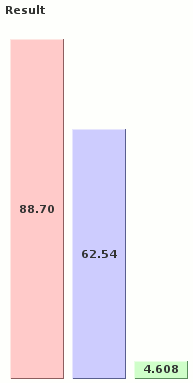{kind=link}