Anatomy of an http URL

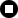

 Anatomy of an
Anatomy of an http URL
The most widely used URL scheme is the http scheme. The
http URL scheme is used to locate documents that reside on
Web servers.
A Web server is more accurately called an HTTP server. HTTP stands for Hypertext Transfer Protocol, and is a protocol designed to transfer hypertext documents over the Internet. It is used to transfer almost all of the documents you download using your Web browser. Knowing a bit about HTTP may be useful for HTML authors, but we won't cover any of it right now.
An http URL may be broken down as shown below:
https://WebReference.com:80/html/tutorial2/2.html?query |--| |--------------||-||--------------------||----| 1 2 3 4 5
The first part, http, is the scheme name, which I
explained previously. It is followed by a colon (:) and two
slash characters (//).
After that follows the hostname of the computer on which the document resides. You probably already know what a hostname is; but just in case you don't, here's a few words on the topic:
Computers on the Internet have a numeric address, called an IP
address. This is a set of four numbers ranging from 0 to 255. For
example, the IP address of the computer on which WebReference.com's HTTP
server is running is:
199.35.192.185
This address acts much like a phone number. If you "dial" this address into your computer's Internet software, it will find out where the computer is and figure out a way to get to it.
The problem with IP addresses is that they are very hard to remember. There's no immediately obvious logic to them, and two related computers might have completely different IP addresses. Also, for technical reasons, there are often times when the IP address of a computer has to be changed. This makes it very difficult to keep track of IP addresses.
So, a system called DNS, or Domain Name Service was created. The purpose of DNS is to translate names for computers into IP addresses. This way, computers can have a name that is easy to remember for humans, and computers can find the IP addresses that they need by consulting DNS.
This address is called an FQDN, or Fully Qualified
Domain Name. A computer's FQDN can be used from anywhere on the
Internet to identify the computer and translate it into an IP address.
For example, WebReference.com's FQDN is
www.webreference.com. Actually, this is just an alias;
computers may have more than one FQDNs that point to the same IP
address. You also can access the same computer with the FQDN
webreference.com instead, because that too is an alias to
the same computer. As a matter of fact, a computer can have many IP
addresses as well, but now I'm getting too technical: the important
thing to remember is that computers on the Internet have IP addresses,
and FQDNs are a way to refer to them that is easier to remember; FQDNs
translate into IP addresses.
Note that FQDNs are case-insensitive.
www.webreference.com is equivalent to
WWW.WEBREFERENCE.COM or www.WebReference.com.
Most of the time, they are written in lowercase, but this doesn't mean
they have to be. Also note that DNS offers a couple of ways of referring
to hosts without their FQDN, but this again is something for the more
technical people (in other words, if you didn't know already, chances
are you don't want to know anyway).
Ending that rather large foray into the world of host naming, the
hostname part of an http URL is anything that can be
considered a valid hostname: an IP address, an FQDN, or one or two other
cases which we won't bother with.
The third part of the URL, which is optional, is the port
number. Internet hosts have a certain number of ports. You can
think of them as those booths you see in a bank. Some offer one type of
service (i.e. deposits), others another type of service (i.e. currency
exchange) and some are just closed. It's the same with Internet hosts -
one port could offer HTTP, another could offer mail routing, and so on.
Ports are numbered, and most services have a pre-defined port that they
usually work from. HTTP usually runs on port 80, but this is not
necessary. If it is running on port 80 in the machine you named in the
hostname part, then you don't need to specify a port number. If it is
running on a different port, a colon (:) followed by the
port number is required to point to that port.
The fourth part is also optional. It is the path to the document you
are requesting. The path is a set of characters separated by slashes
(/). This is roughly analogous to filenames on your hard
disk. There is a root directory, directories after that that may contain
directories or other other documents. Look at the following three
examples:
/ /html/ /html/tutorial2/2.html /html
The first one refers to the root directory. The second one refers to the directory /html/. The third one refers to the document 2.html in the directory /html/tutorial2/. The fourth one, by the way, refers to the document html in the root directory, and not the directory /html/; this is because it does not have a trailing slash character. Although most browsers will happily add the trailing slash when they discover that this is the case, it is still wrong to refer to directories without the trailing slash. It is perfectly possible to have both a directory and a document with the same name in a directory.
Take note that just because pathnames in URLs look a lot like
pathnames in filesystems does not mean that there is a
mapping between the two. Although it is sometimes the case that the
directories and documents specified in URL pathnames correspond directly
to directories and files in the remote computer (such as in the
ftp or file URL schemes, which we'll cover
later on), it is not always the case. It depends entirely on
the scheme and the way this string is handled.
Also note that the path name has nothing to do with the format of the
document returned. In the case of WebReference.com, all of the above
examples will return an HTML document. Also, the "extension" at the end
of the third example (the ".html" part) does not
necessarily indicate the type of document, as it does on some operating
systems like Microsoft Windows. The document
https://WebReference.com/contact.php has an
extension of .cgi, but is still an HTML document.
The fifth and final part of the URL is the query string,
and is also optional. A query string is, essentially, input to a program
that must be evaluated in a certain way. If the Web page described
before the query string is such a program, then this string will make
sense to it and it will return the relevant information. The query
string consists of a question mark (?) followed by a piece
of text that depends entirely on the program set up to handle it.
That's the full syntax of http URLs. You've probably
seen a lot of them if you've been browsing the Web for any amount of
time, so now you know what they mean. Now that you have a firm
understanding of a URL scheme that we can use for examples, it's time to
look at the concept of Relative URLs.
![]()
Produced by Stephanos Piperoglou
All Rights Reserved. Legal Notices.
URL: https://www.webreference.com/html/tutorial2/2.html
Created: June 11, 1998
Revised: June 11, 1998
 Find a programming school near you
Find a programming school near you