WebReference.com - Part 2 of chapter 5 from Information Architecture for the World Wide Web, 2nd Edition. From O'Reilly (3/5).
[previous] [next] |
Information Architecture for the WWW, 2E. Chapter 5: Organization Systems
The Database Model: A Bottom-Up Approach
A database is defined as "a collection of data arranged for ease and speed of search and retrieval." A Rolodex provides a simple example of a flat file database (see Figure 5-14). Each card represents an individual contact and constitutes a record. Each record contains several fields, such as name, address, and telephone number. Each field may contain data specific to that contact. The collection of records is a database.
Figure 5-14: The printed card Rolodex is a simple database
In an old-fashioned Rolodex, users are limited to searching for a particular individual by last name. In a more contemporary, computer-based contact management system, we can also search and sort using other fields. For example, we can ask for a list of all contacts who live in Connecticut, sorted alphabetically by city.
Most of the heavy-duty databases we use are built upon the relational database model. In relational database structures, data is stored within a set of relations or tables. Rows in the tables represent records, and columns represent fields. Data in different tables may be linked through a series of keys. For example, in Figure 5-15, the au_id and title_id fields within the Author_Title table act as keys linking the data stored separately in the Author and Title tables.
So why are database structures important to information architects? After all, we made a fuss earlier in the book about our focus on information access rather than data retrieval. Where is this discussion heading?
In a word, metadata. Metadata is the primary key that links information architecture to the design of database schema. Metadata allows us to apply the structure and power of relational databases to the heterogeneous, unstructured environments of web sites and intranets. By tagging documents and other information objects with controlled vocabulary metadata,[4] we enable powerful searching and browsing. This is a bottom-up solution that works well in large, distributed environments.
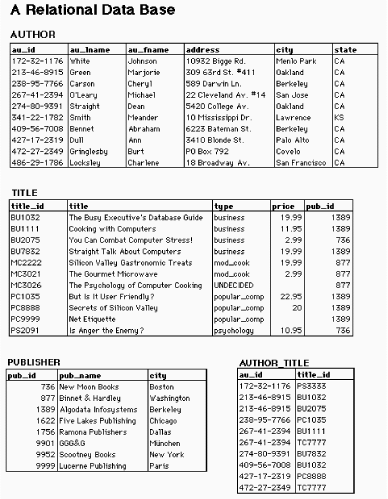
Figure 5-15: A relational database schema (this example is drawn from an overview of the relational database model at the University of Texas at Austin; see https://www.utexas.edu/cc/database/datamodeling/rm/)
The relationships between metadata elements can become quite complex. Defining and mapping these formal relationships requires significant skill and technical understanding. For example, the entity relationship diagram (ERD) in Figure 5-16 illustrates a structured approach to defining a metadata schema. Each entity (e.g., Resource) has attributes (e.g., Name, URL). These entities and attributes become records and fields. The ERD is used to visualize and refine the data model before design and population of the database.
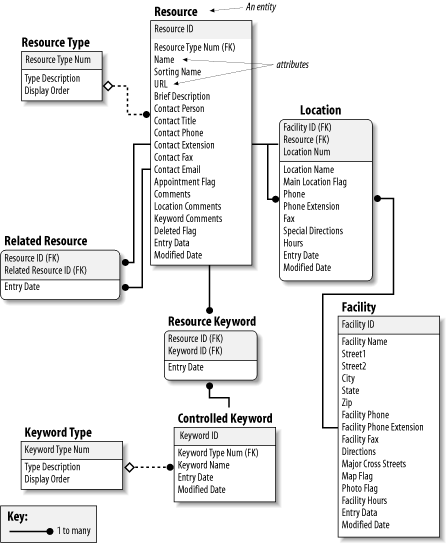
Figure 5-16: An entity relationship diagram showing a structured approach to defining a metadata schema (courtesy of InterConnect of Ann Arbor)
We're not suggesting that all information architects must become experts in SQL, XML schema definition, the creation of entity relationship diagrams, and the design of relational databases, though these are all extremely valuable skills. In many cases, you'll be better off working with a professional programmer or database designer who really knows how to do this stuff. And for large web sites, you will hopefully be able to rely on Content Management System (CMS) software to manage your metadata and controlled vocabularies.
Instead, information architects need to understand how metadata, controlled vocabularies, and database structures can be used to enable:
Automatic generation of alphabetical indexes (e.g., product index)
Dynamic presentation of associative "see also" links
Fielded searching
Advanced filtering and sorting of search results
The database model is particularly useful when applied within relatively homogeneous subsites such as product catalogs and staff directories. However, enterprise controlled vocabularies can often provide a thin horizontal layer of structure across the full breadth of a site. Deeper vertical vocabularies can then be created for particular departments, subjects, or audiences.
4. [Back] Chapter 9 digs much deeper into the use and value of metadata and controlled vocabularies.
[previous] [next] |
Created: September 30, 2002
Revised: September 30, 2002
URL: https://webreference.com/authoring/design/information/iawww/chap5/2/3.html
 Find a programming school near you
Find a programming school near you