Where to use XSLT
Where to use XSLT
In this final section of this chapter I shall try and identify what tasks XSLT is good at, and by implication, tasks for which a different tool would be more suitable. I shall also look at alternative ways of using XSLT within the overall architecture of your application.
Broadly speaking, as I discussed at the beginning of the chapter, there are two main scenarios for using XSLT transformations: data conversion, and publishing; and we'll consider each of them separately.
Data Conversion Applications
Data conversion is not something that will go away just because XML has been invented. Even though an increasing number of data transfers between organizations or between applications within an organization are likely to be encoded in XML, there will still be different data models, different ways of representing the same thing, and different subsets of information that are of interest to different people (recall the example at the beginning of the chapter, where we were converting music between different XML representations and different presentation formats). So however enthusiastic we are about XML, the reality is that there are going to be a lot of comma-separated-values files, EDI messages, and any number of other formats in use for a long time to come.
When you have the task of converting one XML data set into another XML data set, then XSLT is an obvious choice.
|
|
It can be used for extracting the data selectively, reordering it, turning attributes into elements or vice versa, or any number of similar tasks. It can also be used simply for validating the data. As a language, XSLT is best at manipulating the structure of the information as distinct from its content: it's a good language for turning rows into columns, but for string handling (for example removing any text that appears between square brackets) it's rather laborious compared with a language like Perl. However, you can always tackle these problems by invoking procedures written in other languages, such as Java or Javascript, from within the stylesheet.
XSLT is also useful for converting XML data into any text-based format, such as comma-separated values, or various EDI message formats. Text output is really just like XML output without the tags, so this creates no particular problems for the language.
|
|
Perhaps more surprising is that XSLT can often be useful to convert from non-XML formats into XML or something else:
|
|
In this case you'll need to write some kind of parser that understands the input format; but you would have had to do that anyway. The benefit is that once you've written the parser, the rest of the data conversion can be expressed in a high-level language. This separation also increases the chances that you'll be able to reuse your parser next time you need to handle that particular input format. I'll show you an example in Chapter 9, page 610, where the input is a rather old-fashioned and distinctly non-XML format widely used for exchanging data between genealogy software packages. It turns out that it isn't even necessary to write the data out as XML before using the XSLT stylesheet to process it: all you need to do is to make your parser look like an XML parser, by making it implement one of the standard parser interfaces: SAX or DOM. Most XSLT processors will accept input from a program that implements the SAX or DOM interfaces, even if the data never saw the light of day as XML.
One caveat about data conversion applications: today's XSLT processors all rely on holding all the data in memory while the transformation is taking place. The tree structure in memory can be as much as ten times the original data size, so in practice, the limit on data size for an XSLT conversion is a few megabytes. Even at this size, a complex conversion can be quite time-consuming: it depends very much on the processing that you actually want to do.
One way around this is to split the data into chunks and convert each chunk separately – assuming, of course, that there is some kind of correspondence between chunks of input and chunks of output. But when this starts to get complicated, there comes a point where XSLT is no longer the best tool for the job. You might be better off, for example, loading the data into a relational or object database, and using the database query language to extract it again in a different sequence.
If you need to process large amounts of data serially, for example extracting selected records from a log of retail transactions, then an application written using the SAX interface might take a little longer to write than the equivalent XSLT stylesheet, but it is likely to run many times faster. Very often the combination of a SAX filter application to do simple data extraction, followed by an XSLT stylesheet to do more complex manipulation, can be the best solution in such cases.
Publishing
The difference between data conversion and publishing is that in the former case, the data is destined for input to another piece of software, while in the latter case it is destined to be read (you hope) by human beings. Publishing in this context doesn't just mean lavish text and multimedia, it also means data: everything from the traditional activity of producing and distributing reports so that managers know what's going on in the business, to producing online phone bills and bank statements for customers, and rail timetables for the general public. XML is ideal for such data publishing applications, as well as the more traditional text publishing, which was the original home territory of SGML.
XML was designed to enable information to be held independently of the way it is presented, which sometimes leads people into the fallacy of thinking that using XML for presentation details is somehow bad. Far from it: if you were designing a new format for downloading fonts to a printer today, you would probably make it XML-based. Presentation details have just as much right to be encoded in XML as any other kind of information. So we can see the role of XSLT in the publishing process as being converting data-without-presentation to data-with-presentation, where both are, at least in principle, XML formats.
The two important vehicles for publishing information today are print-on-paper, and the web. The print-on-paper scene is the more difficult one, because of the high expectations of users for visual quality. XSL Formatting Objects attempts to define an XML-based model of a print file for high quality display on paper or on screen. Because of the sheer number of parameters needed to achieve this, the standard is taking a while to complete, and will probably take even longer to implement. But the web is a less demanding environment, where all we need to do is convert the data to HTML and leave the browser to do the best it can on the display available. HTML, of course, is not XML, but it is close enough so that a simple mapping is possible. Converting XML to HTML is the most common application for XSLT today. It's actually a two-stage process: first convert to an XML-based model that is structurally equivalent to the target HTML, and then serialize this in HTML notation rather than strict XML.
The emergence of XHTML 1.0 of course tidies up this process even further, because it is a pure XML format, but how quick the take-up of XHTML will be remains to be seen.
When to do the Conversion?
The process of publishing information to a user is illustrated in the diagram below:
|
|
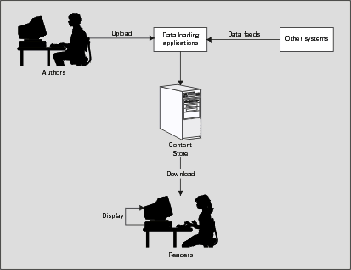
There are several points in such a system where XSLT transformations might be appropriate:
q
Information entered by
authors using their preferred tools, or customized form-filling interfaces, can
be converted to XML and stored in that form in the content store.
q
XML information arriving
from other systems might be transformed into a different flavor of XML for
storage in the content store. For example, it might be broken up into page-size
chunks.
XML can be translated into HTML on the server, when the users request a page. This can be controlled using technology such as Java servlets or Java Server Pages. On a Microsoft server you can use the XSL ISAPI extension available from https://msdn.microsoft.com/xml, or if you want more application control, you can invoke the transformation from script on ASP pages.
XML can be sent down to the client system, and translated into HTML within the browser. This can give a highly interactive presentation of the information, but it relies on all the users having a browser that can do the job.
q
XML data can also be
converted into its final display form at publishing time, and stored as HTML
within the content store. This minimizes the work that needs to be done at
display time, and is ideal when the same displayed page is presented to very
many users.
There isn't one right answer, and often a combination of techniques may be appropriate. Conversion in the browser is an attractive option once XSLT becomes widely available within browsers, but that is still some way off. Even when this is done, there may still be a need for some server-side processing to deliver the XML in manageable chunks, and to protect secure information. Conversion at delivery time on the server is a popular choice, because it allows personalization, but it can be a heavy overhead for sites with high traffic. Some busy sites have found that it is more effective to generate a different set of HTML pages for each section of the target audience in advance, and at page request time, to do nothing more than selecting the right pre-constructed HTML page.
![]()
Produced by Michael Claßen
All Rights Reserved. Legal Notices.
URL: https://www.webreference.com/xml/resources/books/professionalaspxml/31290107.htm
Created: Jan. 05, 2001
Revised: Jan. 05, 2001
 Find a programming school near you
Find a programming school near you