Well-Formed XML
Well-Formed XML
We've discussed some of the reasons why XML makes sense for communicating data, so now let's get our hands dirty and learn how to create our own XML documents. This chapter will cover all you need to know to create "well-formed" XML.
Well-formed XML is XML that meets certain
grammatical rules outlined in the
XML 1.0 specification.
You will learn:
q How to create XML elements using start- and end-tags
q How to further describe elements with attributes
q How to declare your document as being XML
q How to send instructions to applications that are processing the XML document
q Which characters aren't allowed in XML, and how to put them in anyway
Because XML and HTML appear so similar, and because you're probably already familiar with HTML, we'll be making comparisons between the two languages in this chapter. However, if you don't have any knowledge of HTML, you shouldn't find it too hard to follow along.
If you have Internet Explorer 5, you may find it useful to save some of the examples in this chapter on your hard drive, and view the results in the browser. If you don't have IE5, some of the examples will have screenshots to show what the end results look like.
Tags and Text and Elements, Oh My!
It's time to stop calling things just "items" and "text"; we need some names for the pieces that make up an XML document. To get cracking, let's break down the simple <name> document we created in Chapter 1:
<name>
 <first>John</first>
 <middle>Fitzgerald Johansen</middle>
 <last>Doe</last>
</name>
The words between the < and > characters are XML tags. The information in our document (our data) is contained within the various tags that constitute the markup of the document. This makes it easy to distinguish the information in the document from the markup.
As you can see, the tags are paired together, so that any opening tag also has a closing tag. In XML parlance, these are called start-tags and end-tags. The end-tags are the same as the start-tags, except that they have a "/" right after the opening < character.
In this regard, XML tags work the same as start-tags and end-tags do in HTML. For example, you would create an HTML paragraph like this:
<P>This is a paragraph.</P>
As you can see, there is a <P> start-tag, and a </P> end-tag, just like we use for XML.
All of the information from the start of a start-tag to the end of an end-tag, and including everything in between, is called an element. So:
q <first> is a start-tag
q </first> is an end-tag
q <first>John</first> is an element
The text between the start-tag and end-tag of an element is called the element content. The content between our tags will often just be data (as opposed to other elements). In this case, the element content is referred to as Parsed Character DATA, which is almost always referred to using its acronym, PCDATA.
Whenever you come across a strange-looking term like PCDATA, it's usually a good bet the term is inherited from SGML. Because XML is a subset of SGML, there are a lot of these inherited terms.
The whole document, starting at <name> and ending at </name>, is also an element, which happens to include other elements. (And, in this case, the element is called the root element, which we'll be talking about later.)
To put this new-found knowledge into action, let's create an example that contains more information than just a name.
Try It Out – Describing Weirdness
We're going to build an XML document to describe one of the greatest CDs ever produced, Dare to be Stupid, by Weird Al Yankovic. But before we break out Notepad and start typing, we need to know what information we're capturing.
In Chapter 1, we learned that XML is hierarchical in nature; information is structured like a tree, with parent/child relationships. This means that we'll have to arrange our CD information in a tree structure as well.
Since this is a CD, we'll need to
capture information like the artist, title, and date released, as well as the
genre of music. We'll also need information about each song on the CD, such as
the title and length. And, since Weird Al is famous for his parodies, we'll
include information about what song (if any) this one is a parody of.
Here's the hierarchy we'll be creating:
|
|
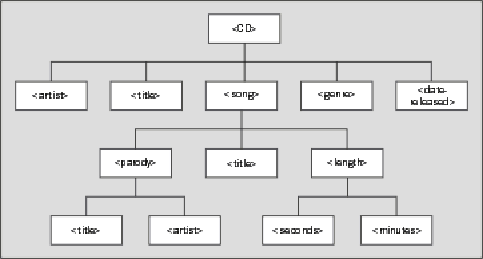
Some of these elements, like <artist>, will appear only once; others, like <song>, will appear multiple times in the document. Also, some will have PCDATA only, while some will include their information as child elements instead. For example, the <artist> element will contain PCDATA for the title, whereas the <song> element won't contain any PCDATA of its own, but will contain child elements that further break down the information.
With this in mind, we're now ready to start entering XML. If you have Internet Explorer 5 installed on your machine, type the following into Notepad, and save it to your hard drive as cd.xml:
<CD>
 <artist>"Weird Al" Yankovic</artist>
 <title>Dare to be Stupid</title>
 <genre>parody</genre>
 <date-released>1990</date-released>
 <song>
   <title>Like A Surgeon</title>
   <length>
     <minutes>3</minutes>
     <seconds>33</seconds>
   </length>
   <parody>
     <title>Like A Virgin</title>
     <artist>Madonna</artist>
   </parody>
 </song>
 <song>
   <title>Dare to be Stupid</title>
   <length>
     <minutes>3</minutes>
     <seconds>25</seconds>
   </length>
   <parody></parody>
 </song>
</CD>
For the sake of brevity, we'll only enter two of the songs on the CD, but the idea is there nonetheless.
Now, open the file in IE5. (Navigate to the file in Explorer and double click on it, or open up the browser and type the path in the URL bar.) If you have typed in the tags exactly as shown, the cd.xml file will look something like this:
|
|

How It Works
Here we've created a hierarchy of information about a CD, so we've named the root element accordingly.
The <CD> element has children for the artist, title, genre, and date, as well as one child for each song on the disc. The <song> element has children for the title, length, and, since this is Weird Al we're talking about, what song (if any) this is a parody of. Again, for the sake of this example, the <length> element was broken down still further, to have children for minutes and seconds, and the <parody> element broken down to have the title and artist of the parodied song.
You may have noticed that the IE5 browser changed <parody></parody> into <parody/>. We'll talk about this shorthand syntax a little bit later, but don't worry: it's perfectly legal.
If we were to write a CD Player application, we could make use of this information to create a play-list for our CD. It could read the information under our <song> element to get the name and length of each song to display to the user, display the genre of the CD in the title bar, etc. Basically, it could make use of any information contained in our XML document.
Rules for Elements
Obviously, if we could just create elements in any old way we wanted, we wouldn't be any further along than our text file examples from the previous chapter. There must be some rules for elements, which are fundamental to the understanding of XML.
XML documents must adhere to these rules to be well-formed.
We'll list them, briefly, before getting down to details:
q Every start-tag must have a matching end-tag
q Tags can't overlap
q XML documents can have only one root element
q Element names must obey XML naming conventions
q XML is case-sensitive
q XML will keep white space in your text
Every Start-tag Must Have an End-tag
One of the problems with parsing SGML documents is that not every element requires a start-tag and an end-tag. Take the following HTML for example:
<HTML>
<BODY>
<P>Here is some text in an HTML paragraph.
<BR>
Here is some more text in the same paragraph.
<P>And here is some text in another HTML paragraph.</p>
</BODY>
</HTML>
Notice that the first <P> tag has no closing </P> tag. This is allowed – and sometimes even encouraged – in HTML, because most web browsers can detect automatically where the end of the paragraph should be. In this case, when the browser comes across the second <P> tag, it knows to end the first paragraph. Then there's the <BR> tag (line break), which by definition has no closing tag.
Also, notice that the second <P> start-tag is matched by a </p> end-tag, in lower case. HTML browsers have to be smart enough to realize that both of these tags delimit the same element, but as we'll see soon, this would cause a problem for an XML parser.
The problem is that this makes HTML parsers much harder to write. Code has to be included to take into account all of these factors, which often makes the parsers much larger, and much harder to debug. What's more, the way that files are parsed is not standardized – different browsers do it differently, leading to incompatibilities.
For now, just remember that in XML the end-tag is required, and has to exactly match the start-tag.
Tags Can Not Overlap
Because XML is strictly hierarchical, you have to be careful to close your child elements before you close your parents. (This is called properly nesting your tags.) Let's look at another HTML example to demonstrate this:
<P>Some <STRONG>formatted <EM>text</STRONG>, but</EM> no grammar no good!</P>
This would produce the following output on a web browser:
Some formatted text, but no grammar no good!
As you can see, the <STRONG> tags cover the text formatted text, while the <EM> tags cover the text text, but.
But is <em> a child of <strong>, or is <strong> a child of <em>? Or are they both siblings, and children of <p>? According to our stricter XML rules, the answer is none of the above. The HTML code, as written, can't be arranged as a proper hierarchy, and could therefore not be well-formed XML.
If ever you're in doubt as to whether your XML tags are overlapping, try to rearrange them visually to be hierarchical. If the tree makes sense, then you're okay. Otherwise, you'll have to rework your markup.
For example, we could get the same effect as above by doing the following:
<P>Some <STRONG>formatted <EM>text</EM></STRONG><EM>, but</EM> no grammar no good!</P>
Which can be properly formatted in a tree, like this:
<P>
 Some
 <STRONG>
   formatted
   <EM>
     text
   </EM>
 </STRONG>
 <EM>
   , but
 </EM>
 no grammar no good!
</P>
An XML Document Can Have Only One Root Element
In our <name> document, the <name> element is called the root element. This is the top-level element in the document, and all the other elements are its children or descendents. An XML document must have one and only one root element: in fact, it must have a root element even if it has no content.
For example, the following XML is not well-formed, because it has a number of root elements:
<name>John</name>
<name>Jane</name>
To make this well-formed, we'd need to add a top-level element, like this:
<names>
 <name>John</name>
 <name>Jane</name>
</names>
So while it may seem a bit of an inconvenience, it turns out that it's incredibly easy to follow this rule. If you have a document structure with multiple root-like elements, simply create a higher-level element to contain them.
Element Names
If we're going to be creating elements we're going to have to give them names, and XML is very generous in the names we're allowed to use. For example, there aren't any reserved words to avoid in XML, as there are in most programming languages, so we have a lot flexibility in this regard.
However, there are some rules that we must follow:
q Names can start with letters (including non-Latin characters) or the "_" character, but not numbers or other punctuation characters.
q After the first character, numbers are allowed, as are the characters "-" and ".".
q Names can't contain spaces.
q Names can't contain the ":" character. Strictly speaking, this character is allowed, but the XML specification says that it's "reserved". You should avoid using it in your documents, unless you are working with namespaces (which are covered in Chapter 8).
q Names can't start with the letters "xml", in uppercase, lowercase, or mixed – you can't start a name with "xml", "XML", "XmL", or any other combination.
q There can't be a space after the opening "<" character; the name of the element must come immediately after it. However, there can be space before the closing ">"character, if desired.
Here are some examples of valid names:
<first.name>
<résumé>
And here are some examples of invalid names:
<xml-tag>Â
which starts with xml,
<123>Â Â Â Â Â
which starts with a number,
<fun=xml>Â
because the "=" sign is illegal, and:
<my tag>Â Â
which contains a space.
Remember these rules for element names – they also apply to naming other things in XML.
Case-Sensitivity
Another important point to keep in mind is that the tags in XML are case-sensitive. (This is a big difference from HTML, which is case-insensitive.) This means that <first> is different from <FIRST>, which is different from <First>.
This sometimes seems odd to English-speaking users of XML, since English words can easily be converted to upper- or lower-case with no loss of meaning. But in almost every other language in the world, the concept of case is either not applicable (in other words, what's the uppercase of b? Or the lowercase, for that matter?), or not extremely important (what's the uppercase of é? The answer may be different, depending on the context). To put intelligent rules into the XML specification for case-folding would probably have doubled or trebled its size, and still only benefited the English-speaking section of the population. Luckily, it doesn't take long to get used to having case-sensitive names.
This is the reason that our previous <P></p> HTML example would not work in XML; since the tags are case-sensitive, an XML parser would not be able to match the </p> end-tag with any start-tags, and neither would it be able to match the <P> start-tag with any end-tags.
Warning! Because XML is case-sensitive, you could legally create an XML document which has both <first> and <First> elements, which have different meanings. This is a bad idea, and will cause nothing but confusion! You should always try to give your elements distinct names, for your sanity, and for the sanity of those to come after you.
To help combat these kinds of problems, it's a good idea to pick a naming style and stick to it. Some examples of common styles are:
q <first_name>
q <firstName>
q <first-name> (some people don't like this convention, because the "-" character is used for subtraction in so many programming languages, but it is legal)
q <FirstName>
Which style you choose isn't important; what is important is that you stick to it. A naming convention only helps when it's used consistently. For this book, I'll usually use the <FirstName> convention, because that's what I've grown used to.
White Space in PCDATA
There is a special category of characters, called white space. This includes things like the space character, new lines (what you get when you hit the Enter key), and tabs. White space is used to separate words, as well as to make text more readable.
Those familiar with HTML are probably quite aware of the practice of white space stripping. In HTML, any white space considered insignificant is stripped out of the document when it is processed. For example, take the following HTML:
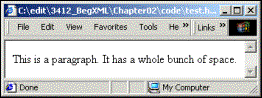
<p>This is a paragraph.      It has a whole bunch
 of space.</p>
As far as HTML is concerned, anything more than a single space between the words in a <p> is insignificant. So all of the spaces between the first period and the word It would be stripped, except for one. Also, the line feed after the word bunch and the spaces before of would be stripped down to one space. As a result, the previous HTML would be rendered in a browser as:
|
|
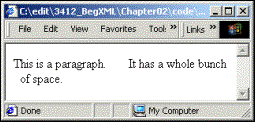
In order to get the results as they appear in the HTML above, we'd have to add special HTML markup to the source, like the following:
<p>This is a paragraph. It has a whole bunch<br>
of space.</p>
specifies that we should insert a space (nbsp stands for Non-Breaking SPace), and the <br> tag specifies that there should be a line feed. This would format the output as:
|
|
Alternatively, if we wanted to have the text displayed exactly as it is in the source file, we could use the <pre> tag. This specifically tells the HTML parser not to strip the white space, so we could write the following and also get the desired results:
<pre>This is a paragraph.      It has a whole bunch
 of space.</pre>
However, in most web browsers, the <pre> tag also has the added effect that the text is rendered in a fixed-width font, like the courier font we use for code in this book.
White space stripping is very advantageous for a language like HTML, which has become primarily a means for displaying information. It allows the source for an HTML document to be formatted in a readable way for the person writing the HTML, while displaying it formatted in a readable, and possibly quite different, way for the user.
In XML, however, no white space stripping takes place for PCDATA. This means that for the following XML tag:
<tag>This is a paragraph.      It has a whole bunch
 of space.</tag>
the PCDATA is:
This is a paragraph.      It has a whole bunch
 of space.
Just like our second HTML example, none of the white space has been stripped out. As far as white space stripping goes, all XML elements are treated just as the HTML <pre> tag. This makes the rules much easier to understand for XML than they are for HTML:
In XML, the white space stays.
Unfortunately, if you view the above XML in IE5 the white space will be stripped out – or will seem to be. This is because IE5 is not actually showing you the XML directly; it uses a technology called XSL to transform the XML to HTML, and it displays the HTML. Then, because IE5 is an HTML browser, it strips out the white space.
End-of-Line White Space
However, there is one form of white space stripping that XML performs on PCDATA, which is the handling of new line characters. The problem is that there are two characters that are used for new lines – the line feed character and the carriage return – and computers running Windows, computers running Unix, and Macintosh computers all use these characters differently.
For example, to get a new line in Windows, an application would use both the line feed and the carriage return character together, whereas on Unix only the line feed would be used. This could prove to be very troublesome when creating XML documents, because Unix machines would treat the new lines in a document differently than the Windows boxes, which would treat them differently than the Macintosh boxes, and our XML interoperability would be lost.
For this reason, it was decided that XML parsers would change all new lines to a single line feed character before processing. This means that any XML application will know, no matter which operating system it's running under, that a new line will be represented by a single line feed character. This makes data exchange between multiple computers running different operating systems that much easier, since programmers don't have to deal with the (sometimes annoying) end-of-line logic.
White Space in Markup
As well as the white space in our data, there could also be white space in an XML document that's not actually part of the document. For example:
<tag>
 <another-tag>This is some XML</another-tag>
</tag>
While any white space contained within <another-tag>'s PCDATA is part of the data, there is also a new line after <tag>, and some spaces before <another-tag>. These spaces could be there just to make the document easier to read, while not actually being part of its data. This "readability" white space is called extraneous white space.
While an XML parser must pass all white space through to the application, it can also inform the application which white space is not actually part of an element's PCDATA, but is just extraneous white space.
So how does the parser decide whether this is extraneous white space or not? That depends on what kind of data we specify <tag> should contain. If <tag> can only contain other elements (and no PCDATA) then the white space will be considered extraneous. However, if <tag> is allowed to contain PCDATA, then the white space will be considered part of that PCDATA, so it will be retained.
Unfortunately, from this document alone an XML parser would have no way to tell whether <tag> is supposed to contain PCDATA or not, which means that it has to assume none of the white space is extraneous. We'll see how we can get the parser to recognize this as extraneous white space in Chapter 9 when we discuss content models.
![]()
Produced by Michael Claßen
All Rights Reserved. Legal Notices.
URL: https://www.webreference.com/xml/resources/books/beginningxml/34120201.htm
Created: Jan. 05, 2001
Revised: Jan. 05, 2001
 Find a programming school near you
Find a programming school near you