Professional Ajax: XML, XPath, and XSLT, Pt. 1
Professional Ajax: XML, XPath, and XSLT, Pt. 1
Reproduced from "Professional Ajax" by Nicholas Zakas, Jeremy McPeak, Joe Fawcett, ISBN: 0471777781, published by WROX. Copyright 2006, Wiley Publishing Inc, used by permission of the publisher. All rights reserved.
As the popularity of XML grew, web developers wanted to use the technology on both the serverand client-side, but only the former initially offered XML functionality. Starting with Internet Explorer 5.0 and Mozilla 1.0, Microsoft and Mozilla began to support XML through JavaScript in their browsers. Recently, Apple and Opera added some XML support to their browsers, albeit not to the extent that Microsoft and Mozilla have. Browser makers continue to broaden the availability of XML support with new features, giving web developers powerful tools akin to those formerly found only on the server.
In this chapter, you will learn how to load and manipulate XML documents in an XML DOM object, use XPath to select XML nodes that meet certain criteria, and transform XML documents into HTML using XSLT.
XML Support in Browsers
Many web browsers are available today, but few have as complete support for XML and its related technologies as Internet Explorer (IE) and Mozilla Firefox. Although other browsers are starting to catch up, with Safari and Opera now able to open XML documents, the functionality is either incomplete or incorrect. Because of these issues, this chapter focuses primarily on the implementations in IE and Firefox.
XML DOM in IE
When Microsoft added XML support to IE 5.0, they did so by incorporating the MSXML ActiveX library, a component originally written to parse Active Channels in IE 4.0. This original version wasn't intended for public use, but developers became aware of the component and began using it. Microsoft responded with a fully upgraded version of MSXML, which was included in IE 4.01.
MSXML was primarily an IE-only component until 2001 when Microsoft released MSXML 3.0, a separate distribution available through the company's web site. Later that year, version 4.0 was released and MSXML was renamed Microsoft XML Core Services Component. Since its inception, MSXML has gone from a basic, non-validating XML parser to a full-featured component that can validate XML documents, perform XSL transformations, support namespace usage, the Simple API for XML (SAX), and the W3C XPath and XML Schema standards, all while improving performance with each new version.
To create an ActiveX object in JavaScript, Microsoft implemented a new class called ActiveXObject that
can be used to instantiate a number of ActiveX objects. Its constructor takes one argument, a string containing
the version of the ActiveX object to create; in this case, it is the version of the XML document.
The first XML DOM ActiveX object was called Microsoft.XmlDom, whose creation looks like this:
var oXmlDom = new ActiveXObject("Microsoft.XmlDom"); |
The newly created XML DOM object behaves like any other DOM object, enabling you to traverse the DOM tree and manipulate DOM nodes.
At the time of this writing, there are five different versions of the MSXML DOM document, and their version strings are as follows:
|

Because there are five different versions, and you presumably always want to use the latest, it is helpful
to use a function to determine which version to use. Doing so ensures you the most up-to-date support
and the highest performance. The following function, createDocument(), enables you to create the correct
MSXML DOM document:
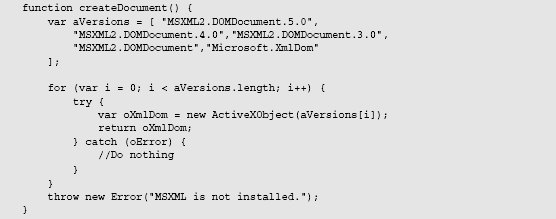
This function iterates through the aVersions array, which contains the version strings of MSXML DOM
documents. It starts with the latest version, MSXML2.DOMDocument.5.0, and attempts to create the
DOM document. If the object creation is successful, it is returned and createDocument() exits; if it
fails, an error is thrown and then caught by the try...catch block, so the loop continues and the next
version is tried. If the creation of an MSXML DOM document fails, a thrown error states that MSXML is
not installed. This function is not a class, so its usage looks like any other function that returns a value:
|
Using createDocument() will ensure that the most up-to-date DOM document is used. Now that you
have an XML document at your disposal, it is time to load some XML data.
Loading XML Data in IE
MSXML supports two methods to load XML: load() and loadXML(). The load() method loads an
XML file at a specific location on the Web. As with XMLHttp, the load() method enables you to load
the data in two modes: asynchronously or synchronously. By default, the load() method is asynchronous;
to use synchronous mode, the MSXML object's async property must be set to false, as follows:
|
When in asynchronous mode, the MSXML object exposes the readyState property, which has the same
five states as the XMLHttp readyState property.
Additionally, the DOM document supports the onreadystatechange event handler, enabling you to
monitor the readyState property. Because asynchronous mode is the default, setting the async property
to true is optional:
oXmlDom.async = true;
oXmlDom.onreadystatechange = function () {
if (oXmlDom.readyState == 4) {
//Do something when the document is fully loaded.
}
};
oXmlDom.load("myxml.xml"); |
In this example, the fictitious XML document named myxml.xml is loaded into the XML DOM. When
the readyState reaches the value of 4, the document is fully loaded and the code inside the if block
will execute.
The second way to load XML data, loadXML(), differs from the load() method in that the former loads
XML from a string. This string must contain well-formed XML, as in the following example:
|
Here, the XML data contained in the variable sXml is loaded into the oXmlDom document. There is no
reason to check the readyState property or to set the async property when using loadXML() because
it doesn't involve a server request.
Traversing the XML DOM in IE
Navigating an XML DOM is much like navigating an HTML DOM: it is a hierarchical node structure. At the
top of the tree is the documentElement property, which contains the root element of the document. From
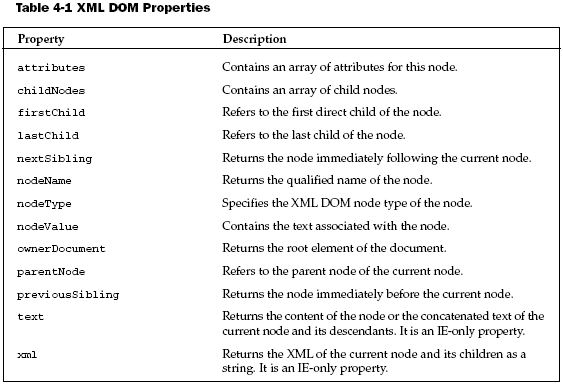
there, you can access any element or attribute in the document using the properties listed in Table 4-1.
Traversing and retrieving data from the DOM is a straight-forward process. Consider the following XML document:
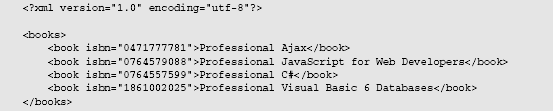
This simple XML document includes a root element, <books/>, with four child <book/> elements.Using this document as a reference, you can explore the DOM. The DOM tree is based on the relationshipsnodes have with other nodes. One node may contain other nodes, or child nodes. Another node may share the same parent as other nodes, which are siblings.
Perhaps you want to retrieve the first <book/> element in the document. This is easily achieved with the firstChild property:

The assignment of the documentElement to oRoot will save space and typing, although it is not necessary. Using the firstChild property, the first <book/> element is referenced and assigned to the variable FirstBook because it is the first child element of the root element <books/>.
You can also use the childNodes collection to achieve the same results:
var oFirstBook2 = oRoot.childNodes[0]; |
Selecting the first item in the childNodes collection returns the first child of the node. Because
childNodes is a NodeList in JavaScript, you can retrieve the amount of children a node has by using
the length property, as follows:
var iChildren = oRoot.childNodes.length;
|
In this example, the integer 4 is assigned to iChildren because there are four child nodes of the document
element.
As already discussed, nodes can have children, which means they can have parents, too. The
parentNode property selects the parent of the current node:
var oParent = oFirstBook.parentNode; |
You saw oFirstBook earlier in this section, but as a quick refresher, it is the first <book/> element in the document. The parentNode property of this node refers to the <books/> element, the documentElement of the DOM.
Created: March 27, 2003
March 6, 2006
URL: https://webreference.com/programming/prof_ajax/1
 Find a programming school near you
Find a programming school near you