WebReference.com - Part 3 of Chapter 10 from Professional PHP4 XML, from Wrox Press Ltd (5/7)
[previous] [next] |
Professional PHP4 XML, Chapter 10: Putting It Together
Using XPath To Query a Document
We haven't considered XPath so far in the chapter because XPath is a standard that is only useful to query an XML document and that's why it makes its stellar appearance in this section.
XPath is a standard to identify and retrieve portions of an XML document using location paths and predicates to filter the results. Many extremists say that XPath is the SQL of XML, but the truth is that many queries and computations can be solved easily using an XPath expression.
We have discussed XPath in detail in Chapter 7.
For our example we could have used the following XPath expression to solve the query:
/cars/car[normalize-space(maxspeed/text())>300 and normalize-space(type/text())='F1']The expression will return all the cars that match the criteria. We can then use the following PHP code to execute the XPath query, and extract the brand and model from the result:
<?php
//$doc = xmldocfile("cars.xml");
$doc = domxml_open_file("cars.xml");
$xpath = $doc->xpath_init();
$ctx = $doc->xpath_new_context();
$result = $ctx->xpath_eval("/cars/car[normalize-space(maxspeed/text())>300
and normalize-space(type/text())='F1']");
$nodes = $result->nodeset;
foreach ($nodes as $node) {
foreach ($node->child_nodes() as $child) {
if ($child->node_type() == XML_ELEMENT_NODE) {
if ($child->tagname() == "brand") {
print ("Brand:");
foreach ($child->child_nodes() as $sub) {
if ($sub->node_type() == XML_TEXT_NODE) {
print ($sub->content);
}
}
print (" / ");
}
if ($child->tagname() == "model") {
print ("Model:");
foreach ($child->child_nodes() as $sub) {
if ($sub->node_type() == XML_TEXT_NODE) {
print ($sub->content);
}
}
print ("<br />");
}
}
}
}
?>The above code produces this simple output for our sampled XML document:
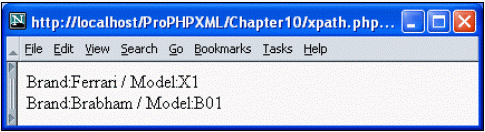
In PHP, the xpath_eval() function is part of the DOM extension, so using XPath implies parsing the XML document into a DOM tree. That's why the XPath function in PHP faces the same problems that we have found when using DOM in the previous example - it can be very resource-consuming or slow for larger documents.
If the document is small- to medium-sized then XPath is usually a very good alternative to query a document, since the query can usually be expressed with a simple expression minimizing the amount of code that we have to write for the query.
If the PHP XPath implementation is slow for large documents we can't blame XPath. It's easy to imagine that a SAX-based XPath processor will be faster than the DOM version, and we may also find an ad-hoc XPath processor, which will be even better.
At the time this book was written the only XPath implementation available for PHP was the
xpath_eval()function in the DOM extension. It's logical to see new XPath processors emerging in the near future for PHP.
Here are some of the advantages and disadvantages of XPath:
| Advantages | Disadvantages |
|---|---|
| A simple expression can solve many queries and computations. | Based on DOM, it inherits DOM's disadvantages - slow for large documents and uses a lot of resources. Thus, it can be unfeasible for huge documents. |
| Very easy to use. | Some complex queries or computations may not be solved with XPath. |
| Solid standard by the W3C. |
[previous] [next] |
Created: August 26, 2002
Revised: August 26, 2002
URL: https://webreference.com/programming/php/php4xml/chap10/3/5.html
 Find a programming school near you
Find a programming school near you