Lucene in Action: Meet Lucene Pt. 2
Lucene in Action: Meet Lucene Pt. 2
Written by Otis Gospodnetic and Erik Hatcher and reproduced from "Lucene in Action" by permission of Manning Publications Co. ISBN 1932394281, copyright 2004. All rights reserved. See https://www.manning.com for more information.
1.5 Understanding the core indexing classes
As you saw in our Indexer class, you need the following classes to perform the simplest indexing procedure:
IndexWriterDirectoryAnalyzerDocumentField
What follows is a brief overview of these classes, to give you a rough idea about their role in Lucene. We'll use these classes throughout this book.
3 Neal Stephenson details this process nicely in "In the Beginning Was the Command Line": https:// www.cryptonomicon.com/beginning.html.
1.5.1 IndexWriter
IndexWriter is the central component of the indexing process. This class creates
a new index and adds documents to an existing index. You can think of IndexWriter as an object that gives you write access to the index but doesn't let you read
or search it. Despite its name, IndexWriter isn't the only class that's used to modify
an index; section 2.2 describes how to use the Lucene API to modify an index.
1.5.2 Directory
The Directory class represents the location of a Lucene index. It's an abstract
class that allows its subclasses (two of which are included in Lucene) to store the
index as they see fit. In our Indexer example, we used a path to an actual file system
directory to obtain an instance of Directory, which we passed to IndexWriter's
constructor. IndexWriter then used one of the concrete Directory implementations,
FSDirectory, and created our index in a directory in the file system.
In your applications, you will most likely be storing a Lucene index on a disk.
To do so, use FSDirectory, a Directory subclass that maintains a list of real files
in the file system, as we did in Indexer.
The other implementation of Directory is a class called RAMDirectory.
Although it exposes an interface identical to that of FSDirectory, RAMDirectory
holds all its data in memory. This implementation is therefore useful for smaller
indices that can be fully loaded in memory and can be destroyed upon the termination
of an application. Because all data is held in the fast-access memory and
not on a slower hard disk, RAMDirectory is suitable for situations where you need
very quick access to the index, whether during indexing or searching. For
instance, Lucene's developers make extensive use of RAMDirectory in all their
unit tests: When a test runs, a fast in-memory index is created or searched; and
when a test completes, the index is automatically destroyed, leaving no residuals
on the disk. Of course, the performance difference between RAMDirectory and
FSDirectory is less visible when Lucene is used on operating systems that cache
files in memory. You'll see both Directory implementations used in code snippets
in this book.
1.5.3 Analyzer
Before text is indexed, it's passed through an Analyzer. The Analyzer, specified
in the IndexWriter constructor, is in charge of extracting tokens out of text to be
indexed and eliminating the rest. If the content to be indexed isn't plain text, it
should first be converted to it, as depicted in figure 2.1. Chapter 7 shows how to
extract text from the most common rich-media document formats. Analyzer is
an abstract class, but Lucene comes with several implementations of it. Some of
them deal with skipping stop words (frequently used words that don't help distinguish
one document from the other, such as a, an, the, in, and on); some deal with
conversion of tokens to lowercase letters, so that searches aren't case-sensitive;
and so on. Analyzers are an important part of Lucene and can be used for much
more than simple input filtering. For a developer integrating Lucene into an
application, the choice of analyzer(s) is a critical element of application design.
You'll learn much more about them in chapter 4.
1.5.4 Document
A Document represents a collection of fields. You can think of it as a virtual document
a chunk of data, such as a web page, an email message, or a text file
that you want to make retrievable at a later time. Fields of a document represent
the document or meta-data associated with that document. The original source
(such as a database record, a Word document, a chapter from a book, and so on)
of document data is irrelevant to Lucene. The meta-data such as author, title,
subject, date modified, and so on, are indexed and stored separately as fields of
a document.
NOTE When we refer to a document in this book, we mean a Microsoft Word,
RTF, PDF, or other type of a document; we aren't talking about Lucene's
Document class. Note the distinction in the case and font.
Lucene only deals with text. Lucene's core does not itself handle anything but
java.lang.String and java.io.Reader. Although various types of documents can
be indexed and made searchable, processing them isn't as straightforward as processing
purely textual content that can easily be converted to a String or Reader
Java type. You'll learn more about handling nontext documents in chapter 7.
In our Indexer, we're concerned with indexing text files. So, for each text file
we find, we create a new instance of the Document class, populate it with Fields
(described next), and add that Document to the index, effectively indexing the file.
1.5.5 Field
Each Document in an index contains one or more named fields, embodied in a
class called Field. Each field corresponds to a piece of data that is either queried
against or retrieved from the index during search.
Lucene offers four different types of fields from which you can choose:
KeywordIsn't analyzed, but is indexed and stored in the index verbatim. This type is suitable for fields whose original value should be preserved in its entirety, such as URLs, file system paths, dates, personal names, Social Security numbers, telephone numbers, and so on. For example, we used the file system path inIndexer(listing 1.1) as aKeywordfield.UnIndexedIs neither analyzed nor indexed, but its value is stored in the index as is. This type is suitable for fields that you need to display with search results (such as a URL or database primary key), but whose values you'll never search directly. Since the original value of a field of this type is stored in the index, this type isn't suitable for storing fields with very large values, if index size is an issue.UnStoredThe opposite ofUnIndexed. This field type is analyzed and indexed but isn't stored in the index. It's suitable for indexing a large amount of text that doesn't need to be retrieved in its original form, such as bodies of web pages, or any other type of text documentTextIs analyzed, and is indexed. This implies that fields of this type can be searched against, but be cautious about the field size. If the data indexed is aString, it's also stored; but if the data (as in ourIndexerexample) is from aReader, it isn't stored. This is often a source of confusion, so take note of this difference when usingField.Text.
All fields consist of a name and value pair. Which field type you should use
depends on how you want to use that field and its values. Strictly speaking,
Lucene has a single Field type: Fields are distinguished from each other based
on their characteristics. Some are analyzed, but others aren't; some are indexed,
whereas others are stored verbatim; and so on.
Table 1.2 provides a summary of different field characteristics, showing you how fields are created, along with common usage examples.
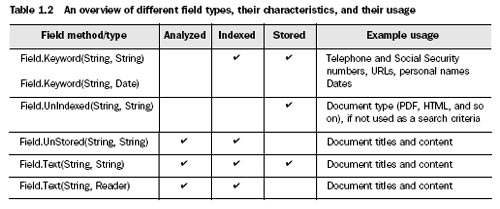
Notice that all field types can be constructed with two Strings that represent the
field's name and its value. In addition, a Keyword field can be passed both a
String and a Date object, and the Text field accepts a Reader object in addition to
the String. In all cases, the value is converted to a Reader before indexing; these
additional methods exist to provide a friendlier API.
- NOTE Note the distinction between
Field.Text(String, String) and Field.
Text(String, Reader). The String variant stores the field data, whereas
the Reader variant does not. To index a String, but not store it, use
Field.UnStored(String, String).Finally, UnStored and Text fields can be used to create term vectors (an advanced
topic, covered in section 5.7). To instruct Lucene to create term vectors for a
given UnStored or Text field, you can use Field.UnStored(String, String, true),
Field.Text(String, String, true), or Field.Text(String, Reader, true).
You'll apply this handful of classes most often when using Lucene for indexing. In order to implement basic search functionality, you need to be familiar with an equally small and simple set of Lucene search classes.
Created: March 27, 2003
Revised: January 31, 2005
URL: https://webreference.com/programming/lucene/2
 Find a programming school near you
Find a programming school near you