PPK on JavaScript: The DOM - Part 1/Page 4
[previous] [next]
PPK on JavaScript: The DOM - Part 1
getElementsByTagName('*');
Finally, you can use getElementsByTagName('*') , which gives you all element nodes in the document in the order they appear in the source code. This method is not used often, since you rarely need all the elements in the entire document. Besides, it is not supported by Explorer 5.5 and earlier.
Examples
For an example, let's look at Usable Forms. When the script starts up, it should go through all tags of a certain kind; if they contain a rel attribute, they should be removed from the document. The script does this through the getElementsByTagName() method:
containers becomes a nodeList that contains all <tr> tags in the entire document. The script goes through them one by one and sees if they have a rel attribute. If so, it removes them from the document and puts them in a waiting room, where they remain until the user checks or selects the appropriate form field.
Sandwich Picker needs a slightly different approach. Initially I only want to go through all <tr>s in the third table on the page, the one that contains the sandwiches. The two other tables also have a few <tr>s, but these contain static information such as the search field and the order form.
So the script goes through the <tr>s in the third table, which has ID="startTable" (well, actually, its <tbody> has this ID, for reasons we'll discuss in section 8E).
Short-distance travel
Every node in the document has five properties and two nodeLists that allow you easy short-distance travel. The five properties are parentNode, firstChild, lastChild, previousSibling, and nextSibling, and they each refer to the node that is the parent node, first child, etc. of the node you use them on.
parentNode, firstChild, lastChild, previousSibling, nextSibling
Take this bit of HTML from Sandwich Picker:
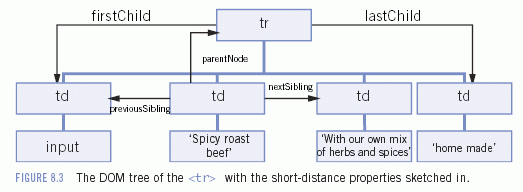
The first <td> is the firstChild of the <tr>; the last <td> is the lastChild. When we start at the second <td>, the <tr> is its parentNode, the first <td> is its previousSibling, and the third <td> is its nextSibling. Almost all nodes contain these five properties, although text nodes cannot have child nodes and document nodes cannot have parent nodes.
childNodes[] and children[]
Every node has two properties that contain nodeLists: childNodes[] and children[]. The difference between the two is that childNodes[] contains all children of a node, while children[] contains only those children that are element nodes themselves, and not the text nodes. children[] is the more useful of the two, since you're rarely interested in text nodes when you go through the children of an element, but unfortunately it is not a part of the W3C DOM specification, and at the time of writing is not supported by Mozilla.
previousSibling, nextSibling, and childNodes[] Are Useless: previousSibling, nextSibling, and childNodes[] appear to be useful properties, but unfortunately they are not nearly as handy as they seem. In the example scripts I use nextSibling twice, and I don't use previousSibling and childNodes[]at all.
The reason is that they generally don't refer to the element nodes you'd expect, but to empty text nodes. We'll study these nuisances in 8H.
Short distance only
Although it's theoretically possible to use these properties to go from any node to any other node, that's not recommended. Take, for instance, this path:
The code is unreadable; no other JavaScript programmer will intuitively understand what you're doing. Besides, even though the path may be correct at the moment you create the script, it doesn't account for changes in the document tree, and changing the document tree is the whole point of W3C DOM scripts.
Therefore, I use these properties exclusively for short-distance travel. In general I restrict myself to two, or at most three, of these properties per statement, because if you need more of them you're usually better served by getElementById() or getElementsByTagName().
Examples
By far the most common use of firstChild is in accessing the text of an element:
If you want to find the text contained by the paragraph, you have to travel to the text node it contains and read out its nodeValue:
You'll also use parentNode a lot. For instance, take this bit of Sandwich Picker:
orderSandwich() is called whenever the user enters text in a form field. The script first checks if the text is a number. If it's not a number, it calls removeFromOrder(); if it is a number, it calls moveToOrder(). this (the form field in which the user entered data) is sent as an argument to both functions.
One of the jobs of the two functions is to highlight or un-highlight the <tr> that contains the form field, and it does so by giving its className a new value. Before that's possible, though, the script has to access the correct <tr>. This is the HTML of one sandwich <tr>:
Therefore, seen from the form field (obj), the
parentNode.parentNode. The form field's parentNode is the <td>, and the <td>'s parentNode is the <tr>.
Since this is short-distance travel, and since the script moves entire <tr>s through the document but doesn't touch the internal structure of the <tr>s, using parentNode.parentNode is safe.
You'll also use parentNode often when you change the document structure, because, as we'll see in Section 8D, all methods you need for structure changes are defined on the parent node of the node you want to change. Suppose you want to remove the node with ID="testID" from the document:
First you access the node (long range!), but in order to execute the removeChild() method, you have to move to its parent first.
Root nodes
Finally, there are two special document properties that allow access to the and
tags: document.documentElement and document.body. The first property exists in all XML documents, since every XML document must have a root element from which all other nodes descend. In HTML pages this is obviously the tag.
document.body is a special addition for HTML pages, since it is often useful to directly access the <body> tag.
[previous] [next]
URL:
 Find a programming school near you
Find a programming school near you