Transparency in Ajax Applications - Part 2/Page 3
[previous]
Transparency in Ajax Applications - Part 2
Sensitive Data Revealed to Users
Programmers often hard code string values into their applications. This practice is usually frowned upon due to localization issues—for example, it is harder to translate an application into Spanish or Japanese if there are English words and sentences hard coded throughout the source code. However, depending on the string values, there could be security implications as well. If the programmer has hard coded a database connection string or authentication credentials into the application, then anyone with access to the source code now has credentials to the corresponding database or secure area of the application.
Programmers also frequently misuse sensitive strings by processing discount codes on the client. Let's say that the music store in our previous example wanted to reward its best customers by offering them a 50-percent-off discount. The music store emails these customers a special code that they can enter on the order form to receive the discount. In order to improve response time and save processing power on the Web server, the programmers implemented the discount logic in the client-side code rather than the server-side code.
The programmers must not have been expecting anyone to view the page source of the order form, because if they had, they would have realized that their "secret" discount code is plainly visible for anyone to find. Now everyone can have their music for half price.
In some cases, the sensitive string doesn't even have to be a string. Some numeric values should be kept just as secret as connection strings or login credentials. Most e-commerce Web sites would not want a user to know the profit the company is making on each item in the catalog. Most companies would not want their employees' salaries published in the employee directory on the company intranet.
It is dangerous to hard code sensitive information even into server-side code, but in client-side code it is absolutely fatal. With just five seconds worth of effort, even the most unskilled n00b hacker can capture enough information to gain unauthorized access to sensitive areas and resources of your application. The ease with which this vulnerability can be exploited really highlights it as a critical danger. It is possible to extract hard coded values from desktop applications using disassembly tools like IDA Pro or .NET Reflector, or by attaching a debugger and stepping through the compiled code. This approach requires at least a modest level of time and ability, and, again, it only works for desktop applications. There is no guaranteed way to be able to extract data from server-side Web application code; this is usually only possible through some other configuration error, such as an overly detailed error message or a publicly accessible backup file. With client-side JavaScript, though, all the attacker needs to do is click the View Source option in his Web browser. From a hacker's point of view, this is as easy as it gets.
Comments and Documentation Included in Client-Side Code
The dangers of using code comments in client code have already been discussed briefly in Chapter 5, but it is worth mentioning them again here, in the context of code transparency. Any code comments or documentation added to client-side code will be accessible by the end user, just like the rest of the source code. When a programmer explains the logic of a particularly complicated function in source documentation, she is not only making it easier for her colleagues to understand, but also her attackers.
In general, you should minimize any practice that increases code transparency. On the other hand, it is important for programmers to document their code so that other people can maintain and extend it. The best solution is to allow (or force?) programmers to document their code appropriately during development, but not to deploy this code. Instead, the developers should make a copy with the documentation comments stripped out. This comment-less version of the code should be deployed to the production Web server. This approach is similar to the best practice concerning debug code. It is unreasonable and unproductive to prohibit programmers from creating debug versions of their applications, but these versions should never be deployed to a production environment. Instead, a mirrored version of the application, minus the debug information, is created for deployment. This is the perfect approach to follow for client-side code documentation as well.
This approach does require vigilance from the developers. They must remember to never directly modify the production code, and to always create the comment-less copy before deploying the application. This may seem like a fragile process that is prone to human error. To a certain extent that is true, but we are caught between the rock of security vulnerabilities (documented code being visible to attackers) and the hard place of unmaintainable code (no documentation whatsoever). A good way to mitigate this risk is to write a tool (or purchase one from a third party) that automatically strips out code comments. Run this tool as part of your deployment process so that stripping comments out of production code is not forgotten.
Security Note
Include comments and documentation in client-side code just as you would with server-side code, but never deploy this code. Instead, always create a comment-less mirrored version of the code to deploy.
Data Transformation Performed on the Client
Virtually every Web application has to handle the issue of transforming raw data into HTML. Any data retrieved from a database, XML document, binary file—or any other storage location—must be formatted into HTML before it can be displayed to a user. In traditional Web applications, this transformation is performed on the server, along with all the other HTML that needs to be generated. However, Ajax applications are often designed in such a way that this data transformation is performed on the client instead of the server.
In some Ajax applications, the responses received from the partial update requests contain HTML ready to be inserted into the page DOM, and the client is not required to perform any data processing. Applications that use the ASP.NET AJAX UpdatePanel control work this way. In the majority of cases, though, the responses from the partial updates contain raw data in XML or JSON format that needs to be transformed into HTML before being inserted into the page DOM. There are many good reasons to design an Ajax application to work in this manner. Data transformation is computationally expensive. If we could get the client to do some of the heavy lifting of the application logic, we could improve the overall performance and scalability of the application by reducing the stress on the server. The downside to this approach is that performing data transformation on the client can greatly increase the impact of any code injection vulnerabilities such as SQL Injection and XPath Injection.
Code injection attacks can be very tedious to perform. SQL Injection attacks, in particular, are notoriously frustrating. One of the goals of a typical SQL Injection attack is to break out of the table referenced by the query and retrieve data from other tables. For example, assume that a SQL query executed on the server is as follows:
An attacker will try to inject her own SQL into this query in order to select data from
tables other than the Customer table, such as the OrderHistory table or the CreditCard table. The usual method used to accomplish this is to inject aUNION SELECT clause into the query statement (the injected code is shown in italics):
The problem with this is that the results of UNION SELECT clauses must have exactly the same number and type of columns as the results of the original SELECT statement. The command shown in the example above will fail unless the Customer and CreditCard tables have identical data schemas. UNION SELECT SQL Injection attacks also rely heavily on verbose error messages being returned from the server. If the application developers have taken the proper precautions to prevent this, then the attacker is forced to attempt blind SQL Injection attacks (covered in depth in Chapter 3), which are even more tedious than UNION SELECTs.
However, when the query results are transformed into HTML on the client instead of the server, neither of these slow, inefficient techniques is necessary. A simple appended SELECT clause is all that is required to extract all the data from the database. Consider our previous SQL query example:
If we pass a valid value like "gabriel" for the CustomerId, the server will return an XML fragment that would then be parsed and inserted into the page DOM.
Now, let's try to SQL inject the database to retrieve the CreditCard table data simply by injecting a SELECT clause (the injected code is shown in italics).
If the results of this query are directly serialized and returned to the client, it is likely that the results will contain the data from the injected SELECT clause.
At this point, the client-side logic that displays the returned data may fail because the data is not in the expected format. However, this is irrelevant because the attacker has already won. Even if the stolen data is not displayed in the page, it was included with the server's response, and any competent hacker will be using a local proxy or packet sniffing tool so that he can examine the raw contents of the HTTP messages being exchanged.
Using this simplified SQL Injection technique, an attacker can extract out the entire contents of the back end database with just a few simple requests. A hack that previously would require thousands of requests over a matter of hours or days might now take only a few seconds. This not only makes the hacker's job easier, it also improves his chances of success because there is less likelihood that he will be caught by an intrusion detection system. Making 20 requests to the system is much less suspicious than making 20,000 requests to the system.
This simplified code injection technique is by no means limited to use with SQL Injection. If the server code is using an XPath query to retrieve data from an XML document, it may be possible for an attacker to inject his own malicious XPath clause into the query. Consider the following XPath query:
An attacker could XPath inject this query as follows (the injected code is shown in italics):
The | character is the equivalent of a SQL JOIN statement in XPath, and the /* clause instructs the query to return all of the data in the root node of the XML document tree. The data returned from this query will be all customers with a customer ID of x (probably an empty list) combined with the complete document. With a single request, the attacker has stolen the complete contents of the back end XML.
While the injectable query code (whether SQL or XPath) is the main culprit in this vulnerability, the fact that the raw query results are being returned to the client is definitely a contributing factor. This design antipattern is typically only found in Ajax applications and occasionally in Web services. The reason for this is that Web applications (Ajax or otherwise) are rarely intended to display the results of arbitrary user queries.
Queries are usually meant to return a specific, predetermined set of data to be displayed or acted on. In our earlier example, the SQL query was intended to return the ID, first name, last name, and phone number of the given customer. In traditional Web applications, these values are typically retrieved by element or column name from the query result set and written into the page HTML. Any attempt to inject a simplified ;SELECT attack clause into a traditional Web application query may succeed; but because the raw results are never returned to the client and the server simply discards any unexpected values, there is no way for the attacker to exploit the vulnerability. This is illustrated in Figure 6-12.
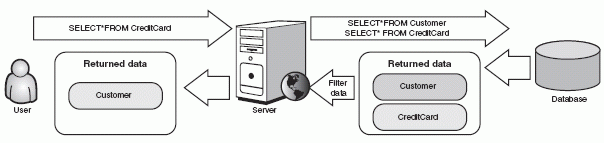
Figure 6-12 A traditional Web application using server-side data transformation will not return the attacker's desired data.
Compare these results with the results of an injection attack against an Ajax application that performs client-side data transformation (as shown in Figure 6-13). You will see that it is much easier for an attacker to extract data from the Ajax application.
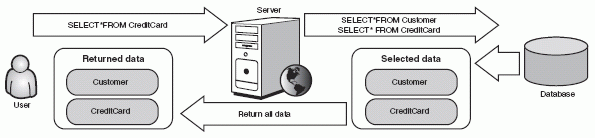
Figure 6-13 An Ajax application using client-side data transformation does return the attacker's desired data.
Common implementation examples of this antipattern include:
|
The solution to this problem is to implement a query output validation routine. Just as we validate all input to the query to ensure that it matches a predetermined format, we should also validate all output from the query to ensure that only the desired data elements are being returned to the client.
It is important to note that the choice of XML as the message format is irrelevant to the vulnerability. Whether we choose XML, JSON, comma-separated values, or any other format to send data to the client, the vulnerability can still be exploited unless we validate both the incoming query parameters and the outgoing results.
Security Through Obscurity
Admittedly, the root problem in all of the specific design and implementation mistakes we've mentioned is not the increased transparency caused by Ajax. In MyLocalWeatherForecast.com, the real problem was the lack of proper authorization on the server. The programmers assumed that because the only pages calling the administrative functions already required authorization, then no further authorization was necessary. If they had implemented additional authorization checking in the server code, then the attacks would not have been successful. While the transparency of the client code did not cause the vulnerability, it did contribute to the vulnerability by advertising the existence of the functionality. Similarly, it does an attacker little good to learn the data types of the server API method parameters if those parameters are properly validated on the server. However, the increased transparency of the application provides an attacker with more information about how your application operates and makes it more likely that any mistakes or vulnerabilities in the validation code will be found and exploited.
It may sound as if we're advocating an approach of security through obscurity, but in fact this is the complete opposite of the truth. It is generally a poor idea to assume that if your application is difficult to understand or reverse-engineer, then it will be safe from attack. The biggest problem with this approach is that it relies on the attacker's lack of persistence in carrying out an attack. There is no roadblock that obscurity can throw up against an attacker that cannot be overcome with enough time and patience. Some roadblocks are bigger than others; for example, 2048-bit asymmetric key encryption is going to present quite a challenge to a would-be hacker. Still, with enough time and patience (and cleverness) the problems this encryption method presents are not insurmountable. The attacker may decide that the payout is worth the effort, or he may just see the defense as a challenge and attack the problem that much harder.
That being said, while it's a bad idea to rely on security through obscurity, a little extra obscurity never hurts. Obscuring application logic raises the bar for an attacker, possibly stopping those without the skills or the patience to de-obfuscate the code. It is best to look at obscurity as one component of a complete defense and not a defense in and of itself. Banks don't advertise the routes and schedules that their armored cars take, but this secrecy is not the only thing keeping the burglars out: The banks also have steel vaults and armed guards to protect the money. Take this approach to securing your Ajax applications. Some advertisement of the application logic is necessary due to the requirements of Ajax, but always attempt to minimize it, and keep some (virtual) vaults and guards around in case someone figures it out.
Obfuscation
Code obfuscation is a good example of the tactic of obscuring application logic. Obfuscation is a method of modifying source code in such a way that it executes in exactly the same way, but is much less readable to a human user.
JavaScript code can't be encrypted because the browser wouldn't know how to interpret it. The best that can be done to protect client-side script code is to obfuscate it. For example,
might be changed to this:
These two blocks of JavaScript are functionally identical, but the second one is much more difficult to read. Substituting some Unicode escape characters into the string values makes it even harder:
a = "\u006c\u0063\u006fme t\u006f J"; b = "\u0061\u006c"; c = "\u0061v\u0061Sc\u0072ipt\u0021\")"; d = "e\u0072t(\"We"; eval(b + d + a + c);There are practically an endless number of techniques that can be used to obfuscate JavaScript, several of which are described in the "Validating JavaScript Source Code" section of Chapter 4, "Ajax Attack Surface." In addition, there are some commercial tools available that will automate the obfuscation process and make the final code much more difficult to read than the samples given here. HTML Guardian™ by ProtWare is a good example. It's always a good idea to obfuscate sensitive code, but keep in mind that obfuscation is not the same as encryption. An attacker will be able to reverse engineer the original source code given enough time and determination. Obfuscating code is a lot like tearing up a bank statement—it doesn't make the statement impossible to read, it just makes it harder by requiring the reader to reassemble it first.
Security Recommendation
Don't
Don't confuse obfuscation with encryption. If an attacker really wants to read your obfuscated code, he will.
Do
Do obfuscate important application logic code. Often this simple step is enough to deter the script kiddie or casual hacker who doesn't have the patience or the skills necessary to recreate the original. However, always remember that everything that is sent to the client, even obfuscated code, is readable.
Conclusions
In terms of security, the increased transparency of Ajax applications is probably the most significant difference between Ajax and traditional Web applications. Much of traditional Web application security relies on two properties of server-side code—namely, that users can't see it, and that users can't change it. Neither of these properties holds true for client-side Ajax code. Any code downloaded to a user's machine can be viewed by the user. The application programmer can make this task more difficult; but in the end, a dedicated attacker will always be able to read and analyze the script executing on her machine. Furthermore, she can also change the script to alter the flow of the application. Prices can be changed, authentication can be bypassed, and administrative functions can be called by unauthorized users. The solution is to keep as much business logic as possible on the server. Only server-side code is under the control of the developers— client-side code is under the control of attackers.

Printed with permission from Addison-Wesley Professional, from the book Ajax Security written by Billy Hoffman and Bryan Sullivan. ISBN 0321491393 &• Copyright © 2007 Addison-Wesley Professional.
 Digg This
Digg This[previous]
URL:
 Find a programming school near you
Find a programming school near you