December 12, 1999 - Document Object Modeling
 |
December 12, 1999 Document Object Modeling Tips: December 1999
Yehuda Shiran, Ph.D.
|
ID and NAME attributes. Each object sports its own properties, methods, and events. You can use the properties to read and update local attributes of the object. You can use the methods to manipulate the object, and take advantage of the events to trigger pre-defined consequences.The Document Object Model is much more general than the DHTML Object Model. It provides a model for the whole document, not just for a single HTML tag. The Document Object Model represents a document as a tree. Every node of the tree represents an HTML tag, or a textual entry inside an HTML tag. The tree structure accurately describes the whole HTML document, including relationships between tags and textual entries on the page. A relationship may be of the type child, parent, or sibling.
The Document Object Model lets you manipulate the document tree. You can create new nodes, delete existing nodes, and move nodes around the tree. The semantics of these operations is exactly what it seems. They add new tags, delete existing tags, and move tags around the document. The DHTML Object Model does not let you modify the document. When using the DHTML Object Model, you are limited to the object you are working with.
Let's take an example:
<HTML>
<HEAD>
<TITLE> Simple DOM Demo </TITLE>
</HEAD>
<BODY ID="bodyNode"><P ID = "p1Node">This is paragraph 1.</P>
This is the document body
<P ID = "p2Node"> </P>
<P ID = "p3Node"></P>
</BODY>
</HTML>
</CENTER>
</BODY>
</HTML>
We have sketched the tree structure of the above example. You can also pop up the page itself to see the outcome of the HTML document above. See the four child nodes (three HTML tags and one text node) of the top level tag. Then, notice the only child of the first of the children.
We have labeled every one of the <P> tags with a unique ID: p1Node, p2Node, and p3Node. Now, suppose you start navigating the tree from p1Node. You can reach the root's second child (a text node) using the nextSibling property: p1Node.nextSibling. The root's third child is reached via:
p1Node.nextSibling.nextSiblingAnd the last root's child can be navigated to using:
p1Node.nextSibling.nextSibling.nextSiblingSuppose the fourth child did have children (which it does not because it is empty). Then the first child would have been accessed as:
p1Node.nextSibling.nextSibling.nextSibling.childNodes[0]
Suppose now that we start our navigation with the third <P>. We can go back to the second <P> by using the previousSibling property:
p3Node.previousSibling.previousSibling.previousSibling.childNodes[0]
Let's start again at the <BODY> tag. It has one grandchild: the content of its first <P> tag. You can reach it via:
bodyNode.firstChild.firstChild
Another navigation direction is the child to parent direction. You can reach each node's parent via the parentNode property. To go from each of the <P> tag to the <BODY> root tag, you would use p1Node.parentNode, p2Node.parentNode, or p3Node.parentNode. You may also take a round trip from the root <BODY> to its grandchild and back by using:
bodyNode.firstChild.firstChild.parentNode.parentNodeTo learn more about DOM Programming, refer to Column 40, The DOM, Part I.
 Find a programming school near you
Find a programming school near you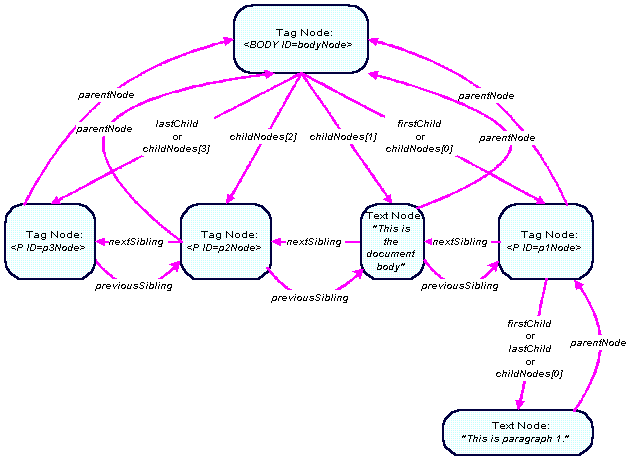{kind=link}