The Inner Workings of Robots, Spiders, and Web Crawlers
The Inner Workings of Robots, Spiders, and Web Crawlers
There are three basic types of search engines: crawler-based, human-powered, and a combination of both.
The human-powered search engines - directories - don't really search. They rely on input from other humans. A Web site URL is submitted manually to the directory, sometimes with a short summary of the site. It's reviewed (though not always) by a human and then indexed. Directory-based search engines include Yahoo, Open Directory, and LookSmart.
The indexes of crawler-based search engines are fed data by computer programs called robots. They are also called spiders or Web crawlers because they 'crawl' over the Web. Google, AllTheWeb, and Teoma are all crawler-based search engines.
| ||||||||||||||||||||||||
According to The Web Robots FAQ, "A robot is a program that automatically traverses the Web's hypertext structure by retrieving a document, and recursively retrieving all documents that are referenced." The robot doesn't physically visit the site, such as a virus would do. It accesses it by requesting documents, much like a Web browser.
There are hundreds, if not thousands, of robots sweeping across the Internet 24/7/365. Their goal is the same: track down information and return it to the sender. Most robots are useful. They feed data to search engines like Google. Many of them are used to map the Internet. Some do a combination of mapping and indexing. A partial list of the robots (user agents) used by search engines is shown at right. A more complete list can be found at the Web Robots Pages.
There are some robots that have a more sinister purpose. Robots like EmailSiphon and Cherry Picker, for instance, are spambots. They're looking to harvest e-mail addresses to add to their spam lists. Those robots scan the page looking for two things:
- E-mail addresses, which are then used as targets for spam.
- Hyperlinks, which the robots then follow, beginning the process again.
For the most part, robots are pretty straightforward when it comes to traversing a Web site. But robots don't think for themselves; they are programmed to operate in a precise manner. They don't understand JavaScript, frames, or Flash very well. They can't access password-protected areas. Often, robots can't properly index a site because there are too many bells and whistles. If they encounter any roadblocks, they move on. They don't try to figure out how to go around them.
When a robot visits a Web site it does one of two things:
- it looks for the robots.txt file and the robots meta tag to see the "rules" that have been set forth, or
- it begins to index the Web pages on your site.
- Googlebot is the actual robot that traverses the Web site. It fetches the pages and send them to the indexer.
- The indexer sorts through every word on the page and stores them in a database.
The graphics below show how a robot typically works (courtesy of Kent State University Library).
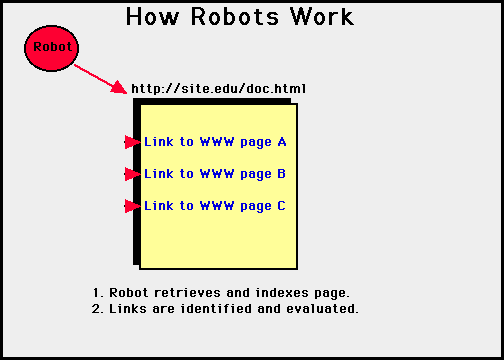
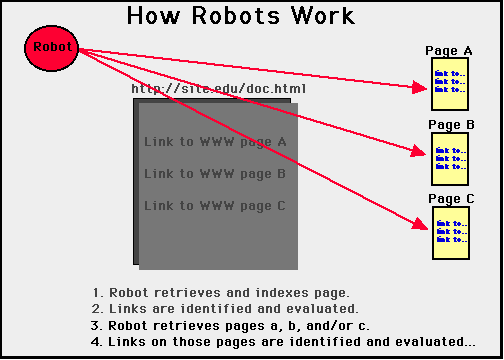
You can tell if your site has been visited by robots by viewing your access
logs. For a more detailed discussion, see "SpiderSpotting:
When a Search Engine, Robot or Crawler Visits." Another good source is "Building
a Better Spider-Trap."
If your Web site is online, robots will eventually come to visit. To expedite the process, most of the crawler-based search engines allow links to be submitted manually. It doesn't mean that you will be listed immediately or even the next day; it can take several weeks (or even months). However, it can help to speed-up the process so they will not have to go looking for you.
Created: August 18, 2004
Revised: August 25, 2004
URL: https://webreference.com/authoring/robots/1
 Find a programming school near you
Find a programming school near you